
Dans cet article, je vais vous exposer une technique que nous avons développée avec mon collègue Laurent Spielmann (@laurent_at_joes) et qui nous permet de simplifier grandement les imports. Elle utilise l’import ODBC.
N’avez-vous jamais été embêté par les incohérences de structure entre une source de données que vous deviez importer et la structure de votre application ?
N’avez-vous jamais maudit le développeur SQL qui utilise comme identifiant unique une concaténation de plusieurs colonnes ?
N’avez-vous jamais craint de modifier le nom d’une rubrique de peur de casser des ordres d’importation ?
N’avez-vous jamais pesté devant la lenteur de synchronisations avec des tables ESS ?
Si vous avez répondu non à toutes ces questions, je vous envie. Cet article est fait pour tous les autres. 🙂
Un peu de technique pour commencer
Connaissez-vous l’histoire de l’ODBC ? Comment il vécut ? Comment il vit encore ?
Et bien écoutez l’histoire de l’ODBC et FileMaker.
Alors voilà, FileMaker a un bon ami, il est puissant et compatible avec plein de bases de données (on s’éloigne un peu de Gainsbourg, mais ça allait commencer à être pénible) : l’ODBC.
L’ODBC est présent de 3 manières bien distinctes dans FileMaker, et il est très important de ne pas confondre :
- FileMaker peut être une SOURCE de données ODBC. Dans ce qui nous occupe aujourd’hui, c’est intéressant parce qu’une base de données FileMaker comme source de données ne sera pas différente d’une autre base de données. Un driver ODBC est fourni avec FileMaker Pro et FileMaker Server.

- FileMaker peut exploiter une source de données ODBC dans le cadre de l’ESS (External SQL Source). Le but est ici d’interagir avec des données externes comme avec des données FileMaker (en créant des occurrences de table, des modèles, et en permettant aux commandes et scripts d’agir sur ces données). Depuis FileMaker 9, nous avions à notre disposition mysql, Oracle et SQL Server. Depuis FileMaker 15 Postgresql et DB2 sont de la partie. Notons que sur Mac un driver de chez Actual technologies est nécessaire. Depuis l’apparition de l’ESS, les développeurs FileMaker ont tendance à l’utiliser pour toute interaction avec les sources SQL. Or c’est une très mauvaise idée, car si la similarité des traitements avec les données FileMaker est quasiment magique, le revers de la médaille est la performance, très, très en dessous des capacités de l’ODBC.
- Enfin, et c’est vraiment la grande oubliée, et donc le sujet de cet article, la possibilité pour FileMaker d’interagir avec une base de données ODBC par script.
De quels pas de script parle-t-on ?
Deux pas de script permettent d’interagir avec une source de données ODBC :
– en lecture : Importer enregistrements.
– en écriture : Exécuter SQL (attention, on parle bien du pas de script et non de la fonction de calcul ExecuterSQL, qui ne fait que lire (SELECT))
On notera qu’il n’est pas possible de lire des données d’une source externe sans les écrire dans une table FileMaker (importer). On aurait pu espérer que Exécuter SQL qui lance bien, comme on peut l’observer dans les logs d’un serveur SQL, une requête de lecture (SELECT), soit capable de retourner le résultat de cette sélection, mais ça n’est pas le cas. C’est bien dommage, mais si on le sait… (astuce : vous pouvez même utiliser Exécuter SQL pour modifier la structure d’une base. Revenez à cette astuce après lecture de l’article, et ça devrait vous donner quelques idées)
Driver ? DSN ? c’est quoi donc ?
La raison principale pour laquelle ces fonctionnalités ont été si négligées est qu’elles demandent l’installation d’un DSN (Data Source Name), et parfois, selon les sources de données, d’un driver spécifique.
Un DSN est le moyen qu’utilise le système d’exploitation pour donner accès aux applications à une source de données ODBC, ODBC étant lui-même un système d’interopérabilité des bases de données entre elles. (Open DataBase Connectivity).
Sur Mac, cela se configure avec ODBC Manager, que l’on trouvait dans le dossier Utilitaires du dossier Applications avant qu’Apple ne décide de supprimer cette fonctionnalité. Heureusement, contrairement au MagSafe, vous pouvez encore le télécharger ici.
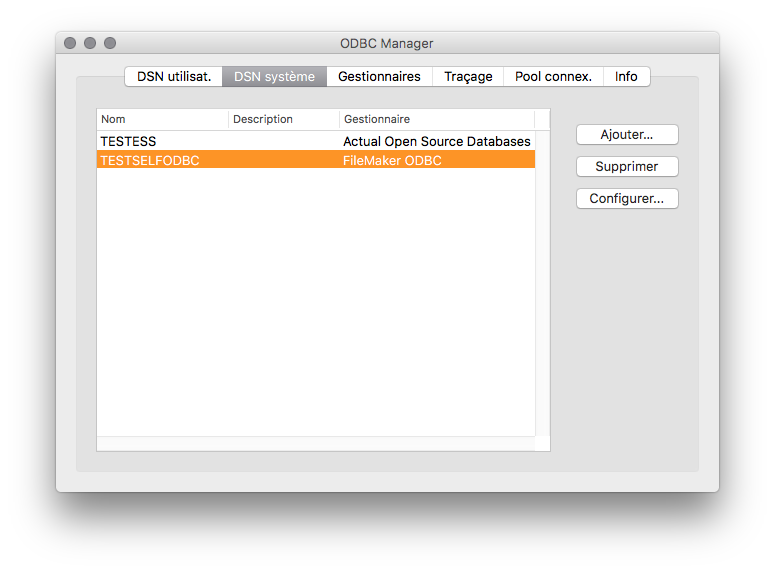
Or s’il est complexe de déployer ce DSN sur tous les postes clients, il est très simple de le faire sur le serveur.
Il se trouve que depuis FileMaker Server 9, on peut programmer des scripts sur serveur, et que depuis FileMaker Server 13, on peut exécuter un script sur serveur à la demande depuis le client (Exécuter script sur serveur).
D’autre part, alors que Importer des enregistrements depuis une source ODBC a toujours été compatible serveur, Exécuter SQL n’est compatible que depuis FileMaker 15. De quoi se re-poser certaines questions !
Pour dire les choses très rapidement : il est possible de ne configurer le DSN que sur le poste serveur et d’en faire bénéficier tous les postes client (y compris Go, WebDirect, et publication web personnalisée).
Toutefois, le développeur aura également besoin d’accéder aux sources de données afin d’écrire ses scripts : rien de plus simple, il suffit de configurer le DSN sur sa machine également, en prenant bien soin d’utiliser exactement le même nom. Ainsi vous pourrez composer vos scripts et le serveur pourra les exécuter.
Voilà pour la “plomberie”. Maintenant nous pouvons nous concentrer sur l’intéressant.
La situation
Voici donc un bref exposé de notre problématique. Nous devons importer des données depuis une base de données mysql.
Le volume est très important, ce qui exclut directement ESS (et d’ailleurs, on n’avait vraiment aucune raison d’utiliser ESS). J’insiste : cette technologie n’a pour but QUE de présenter et manipuler des données externes dans FileMaker comme s’il s’agissait de données FileMaker. Elle n’est absolument pas faite pour des imports ou des synchronisations. Elle est très lente et absolument à proscrire pour cette exploitation. On s’oriente donc directement vers un import ODBC. Mais les subtilités viennent ensuite.
Premier problème : la clef unique et la performance
Nous voici donc partis avec la configuration du pas de script suivant :

Comme vous le voyez, on s’adresse à un DSN avec un requête, ici définie dans une variable par soucis de lisibilité.
Mais parmi les nombreux imports que nous devons réaliser, certains sont de type “mise à jour” (avec la 3ème option cochée dans la fenêtre de définition de l’ordre d’importation)
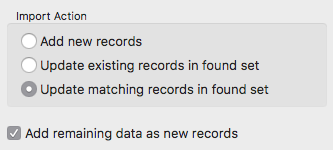
Le problème est que le critère d’unicité ne tient pas dans une seule colonne. Pour décider si un enregistrement correspond et doit être mis à jour, il faut que 3 critères soient égaux.
FileMaker permet tout à fait cela, mais au prix de performances catastrophiques. Au vu du volume (on parle en centaines de milliers d’enregistrements par jour), c’est tout simplement impossible.
Imaginons la requête :
SELECT a, b, c, d FROM myTable
Mais bien que nous voulions importer ces 4 colonnes dans 4 rubriques FileMaker A, B, C et D, nous devons mettre les enregistrements à jour si a, b et c sont identiques à A, B et C.
Nous pouvons configurer l’ordre d’importation ainsi :
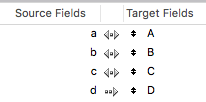
mais nous savons que les performances ne seront pas acceptables.
Une solution serait de demander au développeur de la vue mysql d’ajouter une colonne qui concatènerait les trois qui nous intéressent. Dans notre cas, c’est envisageable, mais dans bien des cas, on s’adresse à une base de données dont on ne maîtrise pas la structure.
Voyons si nous ne pourrions pas faire travailler mysql pour nous…
Tout d’abord, créons une rubrique calculée dans FileMaker qui jouera le rôle de critère d’unicité.
K est une rubrique calculée telle que
A & B & C
Maintenant, modifions la requête SQL ainsi :
SELECT CONCAT (a, b, c) AS K, a, b, c, d FROM myTable
Explication :
- nous créons à la volée une 5ème colonne (résultat de la concaténation de a, b, c, d).
- nous la plaçons en 1ère position (facultatif, c’est juste histoire de prouver qu’on a le contrôle)
- on la renomme en K pour faire joli (mais on va voir que l’esthétique donne des idées)
Résultat, sélectionnant l’option Matching names (noms concordants), on arrive à ceci :
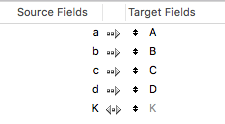
et ça, c’est très, très nettement plus performant !
Deuxième problème: le nommage
Oh ! mais c’est intéressant ce qu’on vient de voir. D’accord nous avons résolu notre problème de performance, mais en plus on a pris le contrôle des noms de champs à gauche (source). Or un des grands problèmes que nous avons avec les imports dans FileMaker, c’est la fragilité. Le seul moyen de maintenir un ordre d’importation même quand on crée ou qu’on supprime une rubrique, c’est de choisir l’option Noms concordants (Matching names), mais alors on s’expose aux changements de noms de part et d’autre.
Or on vient de voir qu’on pouvait contrôler le nom des colonnes à gauche. Ceux qui ont déjà importé des données XML à l’aide d’XSLT le savaient déjà, mais ça mérite quand même d’être précisé.
Dans notre exemple, que j’ai volontairement simplifié en nommant les colonnes a, b, c, d et les rubriques A, B, C, D, les noms n’étaient pas exactement ceux-ci, comme vous vous en doutez.
Imaginons donc que ma requête d’origine ait été :
SELECT name_first, name_last, jobTitle, date_of_birth FROM PEOPLE
et que mes rubriques de destination aient été
prenom, nom, profession, dateDeNaissance
Je peux très bien écrire :
SELECT name_first AS prenom, name_last AS nom, jobTitle as profession, date_of_birth as dateDeNaissance FROM PEOPLE
et avec la concaténation :
SELECT CONCAT (name_first, name_last, jobTitle) AS K, name_first AS prenom, name_last AS nom, jobTitle as profession, date_of_birth as dateDeNaissance FROM PEOPLE
Fantastique ! on peut donc maintenant utiliser l’option Noms concordants !
Reste que, et c’était tout à fait notre cas ici, on sait qu’il peut passer par la tête de notre développeur SQL de changer le nom de ses colonnes. Voire, c’était ici prévu, de changer complètement la structure des vues au bout de quelques semaines d’exploitation. Nous allons donc prendre les devants et créer un système qui permettra de résister à ce genre de choses, c’est-à-dire que l’on veut être capable, en quelques minutes, de changer la source de données et d’adapter notre code, sans, justement, coder. C’est ici que notre travail commence.
La petite technique de derrière les fagots
Ne serait-ce pas idéal si chaque table FileMaker était capable de générer son propre ordre d’importation ?
On a vu que la partie gauche de l’ordre d’importation pouvait être contrôlée “à la volée”. C’est donc à la partie droite (la structure de la table) de contenir l’information.
Un endroit pour cela : les commentaires de rubrique.
Développons donc une petite syntaxe qui va nous permettre :
- de déclarer le nom de la colonne à gauche : nous utiliserons “SOURCENAME:” suivi du nom de la colonne à importer.
- de modifier facilement ce nom : il suffit donc de changer le mot qui suit cette balise.
- d’être désactivable (notion de mise en commentaire) : si la marque de commentaire // est trouvée avant la balise SOURCENAME:, celle-ci est ignorée
- de ne pas interférer avec d’autres informations éventuellement contenues dans le commentaire : on peut, comme vous le voyez sur l’image, ajouter d’autres choses dans le commentaire.

Ensuite, créons une fonction personnalisée telle que : (le code est disponible dans ce fichier texte)
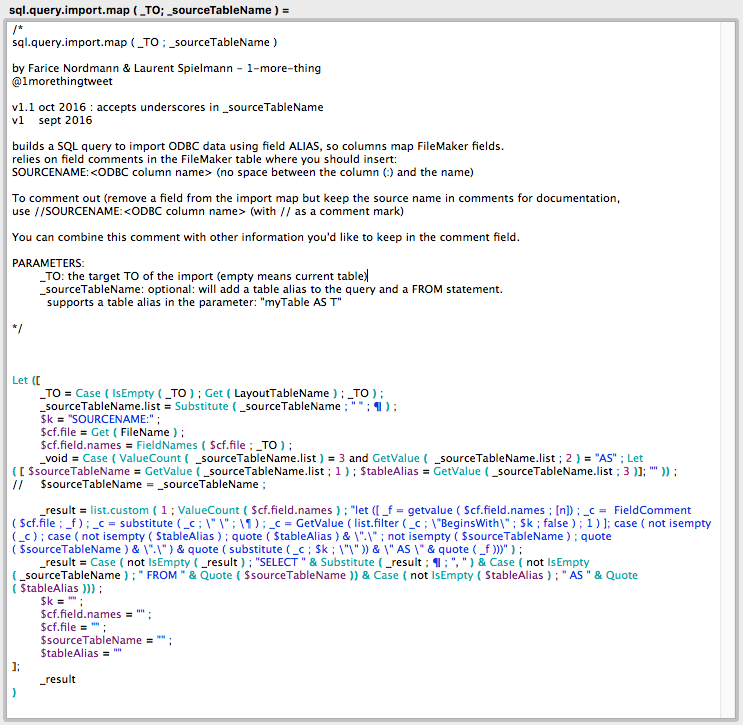
ça a l’air compliqué comme ça, mais il faut préciser :
- qu’une partie non négligeable du travail est faite par deux autres fonctions personnalisées d’Agnès Barouh, CustomList et FilterList, que nous avons pris la liberté de renommer list.custom et list.filter. Entre parenthèses, Agnès développe désormais le Ti’Sac, que nous vous recommandons pour de vrai (et ça n’est pas juste par politesse : c’est un concept de sac à main absolument unique). À l’approche de Noël, vous devriez faire un tour ici.

- que si ça n’était pas un peu compliqué, vous ne nous aimeriez plus.
En fait, peu importe ce qu’il y a dans cette fonction. Si pour la table précédente on évalue le calcul suivant :
sql.query.import.map ( "" ; "contacts AS C" )
le paramètre vide indique “la table active”. On peut aussi écrire :
sql.query.import.map ( "people" ; "contacts AS C" )
le résultat de la fonction est :
SELECT "C"."CIE" AS "company", "C"."familyname" AS "name" FROM "contacts" AS "C"
soit exactement la requête qu’il faut passer à l’instruction Importer enregistrements pour avoir quelque chose de cohérent à droite et à gauche.
Je vous remets l’image correspondant au commentaires de rubriques pour bien comprendre :
- La rubrique ‘company’ va être alimentée par la colonne ‘CIE’
- La rubrique ‘excluded’ ne fait pas partie de l’ordre d’importation
- La rubrique ‘inactive’ non plus
- La rubrique ‘name’ va recevoir la colonne ‘familyname’
Le tout en évitant les mots réservés en SQL (les noms des colonnes sont entre guillemets).
Le deuxième paramètre, “contacts AS C”, aurait pu être écrit “contacts”, mais la fonction supporte les alias de table. Ceci dans le but d’importer depuis des jointures (ce qui n’est pas actuellement supporté par la fonction)
Enfin, ce deuxième paramètre est facultatif, ce qui vous permet d’injecter des fonctions SQL à votre requête :
sql.query.import.map ( "" ; "" )
retourne :
SELECT "CIE" AS "company", "familyname" AS name
Si vous avez besoin de faire des choses plus complexes, vous pouvez donc écrire :
sql.query.import.map ( "" ; "" ) & ", CONCAT ( colonne1, colonne2 ) AS maRubrique FROM contacts"
Comme vous le voyez, cette technique ouvre beaucoup de possibilités. Que ce soit lors d’imports depuis une autre base de données ou depuis la base de données elle-même.
Si vous combinez cela au fait qu’un import est capable de créer une nouvelle table, qu’Exécuter SQL est capable de supprimer cette table (DROP), que vous pouvez désormais dupliquer un ensemble d’enregistrements sans être bloqué par le fait qu’une table ne peut s’importer dans elle-même, etc, etc… les possibilités sont immenses !
Nous espérons vous avoir fait découvrir quelque chose. N’hésitez pas à laisser un commentaire ci-dessous ou à partager. À vous maintenant d’explorer !


