[vc_row bg_color=””][vc_column][vc_column_text]
Claris vient d’annoncer la sortie de FileMaker 2025 (nom commercial de la version 22). Comme il est de coutume, vous retrouverez dans cet article les nouveautés et un point de vue critique pour, d’une part, essayer d’analyser la direction prise, et d’autre part vous permettre d’appréhender ces nouveautés.
Généralités importantes
Commençons par quelques remarques très importantes à lire avant de franchir le pas.
- FileMaker Server 2025 ne permet les connexions que depuis FileMaker Pro 2024 (21) et 2025 (22). Attention donc si vous avez encore des parcs avec de plus anciennes versions
- En revanche, à partir de la 22, la mise à jour inApp supportera les versions majeures. Cela simplifiera le maintien à jour du parc logiciel.
- Très important – et qui ne facilitera pas les transitions si, justement, vous avez des versions disparates : sous Windows il sera désormais impossible d’installer FileMaker Pro 2025 aux côtés de plus anciennes versions. FileMaker Pro 22 devrait remplacer les anciennes versions (je n’ai pour ma part pas testé cela, n’hésitez pas à réagir pour compléter cette information).
- À prendre en compte avant de faire la mise à jour de votre serveur, si vous utilisez OData : il y a de grandes améliorations mais aussi quelques changements qui pourraient perturber les systèmes existants (voir paragraphe sur FileMaker Server en fin d’article)
Aussi, c’est la première fois que les interfaces pour Windows et pour Mac divergent. La version mac apporte de nombreuses nouveautés qui tendent à se rapprocher des applications Apple telles que Keynote, Pages ou Numbers – mais cela concerne la partie “développeur” (on reviendra dans le détail). Mais c’est aussi l’interface utilisateur qui change avec la nouvelle barre d’outils. J’avoue ne pas bien comprendre ce qui empêchait de remplacer les icônes sur PC également afin de maintenir une cohérence.
[/vc_column_text][/vc_column][/vc_row][vc_row bg_color=””][vc_column][vc_column_text]
IA, IA, IA
Déjà largement présente avec la version 21 (on l’a peut-être oublié, mais l’IA est au sein de FileMaker depuis la version 19 en 2020 avec CoreML), l’intelligence artificielle est la grande star de cette version 2025.
Je ne vais pas ici rentrer dans le détail de l’implémentation car elle comporte d’innombrables fonctions et pas de scripts – pour une lecture détaillée des nouveautés, je vous recommande toujours la lecture des notes de version publiées par Claris – mais de manière générale on peut dire ceci :
- on est dans la continuité de ce qui était déjà présent en version 21, à savoir une priorité donnée à l’utilisateur final pour interagir avec les données, plutôt qu’un mode “agentic” permettant au développeur de générer du code ou des interfaces automatiquement. Personnellement, cela me semble être la bonne stratégie, le “code” FileMaker étant déjà si rapide à produire, mais on peut déduire des immenses progrès faits dans la représentation XML d’un fichier (grosses évolutions du XML quand on sauve une copie en XML, avancées de l’utilitaire Upgrade Tool, intégré à FileMaker Server…) que Claris est en train de préparer l’arrivée de l’assistant au développeur.
- les principales nouveautés sont :
- RAG (pour limiter les réponses d’un LLM à des informations trouvées dans un corpus de données précis (vos documents, votre site web…) afin d’obtenir des réponses précises et d’éviter les hallucinations.
- recherche sémantique (texte et images) côté serveur
- génération de requêtes SQL en langage naturel
- implémentation des modèles directement sur FileMaker Server. Certains modèles sont même livrés avec l’installeur de FileMaker Pro pour une encore plus grande facilité.
Sur ce dernier point, qui se caractérise par un nouvel onglet de la console d’administration du serveur, d’où l’on peut activer des modèles d’IA installés localement, on peut contester la pertinence. En effet, si cela a l’immense avantage d’être ultra-simple, il est très difficile, voire impossible, de contrôler la répartition des ressources entre en les modèles d’IA et FileMaker Server lui-même. Ainsi, à moins d’utiliser un serveur local grandement fourni en RAM et en VRAM – un mac Studio par exemple -, on peut très vite pénaliser l’exécution normale de FileMaker Server. On peut parier que dans un avenir proche, une machine secondaire pourra être désignée pour faire tourner l’IA, à l’image de ce que l’on peut déjà faire avec Web Direct. Pour l’heure, les principaux services d’hébergement, dont notre service fmcloud.fm, ont choisi de masquer cet onglet et de ne le proposer que dans des configurations “custom”.
[/vc_column_text][vc_column_text]
Localisation en français revue
C’est un petit point, mais qu’il fallait bien mentionner quelque part : j’ai proposé à Claris de revoir un grand nombre de traductions et d’abréviations inutiles qui étaient présentes dans l’interface en français. Un grand nombre de ces modifications ont été appliquées, pour une plus grande clarté et une meilleure cohérence. La plupart de ces modifications vous sembleront parfaitement naturelles et vous ne les remarquerez même pas. J’attire toutefois votre attention sur les fonctions ObtenirTexteDynamique et ObtenirTexteDynamiqueEnJson où “TexteDynamique” remplace “TexteEnDirect” pour respecter la traduction d’Apple de sa technologie LiveText, mais qui pourrait vous laisser chercher ces fonctions longtemps.
[/vc_column_text][vc_column_text]
Navigation dans les ensembles trouvés (found sets)
Immense nouveauté : la possibilité de mémoriser et restituer une liste d’enregistrements, en utilisant l’ID interne des enregistrements, tels que retournés par la fonction Get ( RecordID ) / Obtenir ( IDenregistrement )
La fonction GetRecordIDsFromFoundSet ( type ) / ObtenirIDEnregistrementDansJeuTrouvé retourne un texte ou un tableau JSON (array) en fonction du paramètre type.
[/vc_column_text][ish_table header_bg_color=”color2″ border_color=”color5″]
| Valeur du paramètre | Forme du résultat |
|---|---|
| 0 | liste d’IDs séparés par un retour chariot – ¶ ou Char (13) : 75¶76¶77¶78¶79¶81¶83¶87¶88¶89 |
| 1 | tableau JSON des IDs sous forme de strings (je ne comprends pas l’intérêt) |
| 2 | tableau JSON des IDs sous forme de nombres |
| 3 | liste des intervalles séparés par un retour chariot : 75-79¶81¶83¶87-89 |
| 4 | tableau JSON des intervalles |
[/ish_table][vc_column_text]
Retenez les points suivants :
- la fonction retourne un résultat immédiat, car elle ne fait pas appel à la “couche” données. Aucun téléchargement de données entre le serveur et le client n’est nécessaire
- l’ordre de tri est respecté, mais il n’existe aucune information de contexte (ni table, ni modèle, ni… ordre de tri : les enregistrements sont dans le bon ordre mais on n’a pas les critères de tri).
- il n’existe pas de fonction pour passer d’une notation liste (ou tableau) à son équivalent avec les intervalles, et vice versa. Il faut donc savoir ce que l’on veut faire lors de la restitution dès le moment de sa mémorisation (pour une restitution simple, la notation avec les intervalles est bien plus efficace (prend beaucoup moins de place), mais si vous comptez utiliser l’action de script Activer les enregistrements liés, alors vous avez besoin de la liste complète des IDs.
Restitution : comme il est logique, la restitution de cet ensemble d’enregistrements se fait avec l’action de script Go to list of records, qui prend en paramètre n’importe quelle variante du résultat de la fonction ci-dessus, et permet de sélectionner le modèle de destination et d’ouvrir une nouvelle fenêtre.
L’utilisation de ce pas de script ainsi que la gestion d’erreur a été harmonisée avec Activer les enregistrements liés.
Remarque : si l’ordre de tri n’est pas l’ordre naturel, soit que les enregistrements eussent été triés à l’origine, soit que l’on aura manipulé l’ordre “manuellement”, par exemple avec un calcul du type : “3¶1¶2” – car oui, il est possible de définir un ordre qui ne pourrait être obtenu par un tri naturel – alors l’ensemble restitué sera semi-trié. C’est très important car, ne disposant pas des critères de tri à l’origine, FileMaker ne peut véritablement trier. Il faut donc prendre en compte que les sous-récapitulatifs après tri ne seront pas affichés, ou que la fonction GetSummary / Recapitulatif ne fonctionnera pas.
Pourquoi est-ce si important ?
- En combinaison avec l’exécution de scripts sur serveur et aux transactions, il devient extrêmement aisé de déléguer au serveur le traitement d’un ensemble d’enregistrements. Cette fonction personnalisée (c’est cadeau !) vous permettra de plus d’inclure plus d’information sur l’ensemble trouvé.
- Vous pouvez mémoriser facilement de nombreux ensembles, afin, par exemple, de revenir en arrière dans un historique de navigation
- Bien que toutes les fonctions d’un snapshot ne soient pas présentes (tri, alerte en cas d’enregistrements supprimés…), il est possible de communiquer un ensemble d’enregistrements, et ce sans faire appel au système de fichier. Ainsi, c’est utilisable en Web Direct.
[/vc_column_text][vc_column_text]
Remplacer contenu de rubrique sans exécuter les auto-entrées
Pour moi, c’est ici la nouveauté la plus “révolutionnaire”. Elle figurait en tête de mes “feature requests” depuis bien longtemps. On peut maintenant, uniquement dans le cadre d’un script, éviter l’exécution des auto-entrées lors du remplacement du contenu d’une rubrique (Replace Field Contents).
Cas d’utilisation :
- Après une migration de données d’une ancienne application à une nouvelle : corrigez les données sans modifier les horodatages de modification.
- Populez une nouvelle rubrique sur les anciens enregistrements.
Conseil :
Si vous avez un menu personnalisé pour les développeurs, remplacez la commande Remplacer par un script avec une seule instruction : Remplacer contenu rubrique. Ainsi, en tant que développeur, vous aurez la possibilité de cocher ou non la case pour exécuter les auto-entrées.
Remarque : Nous avons désormais trois pas de scripts permettant d’éviter les auto-entrées : Importer enregistrements, Ouvrir transaction, Remplacer contenu rubrique.
[/vc_column_text][vc_column_text]
JSONParse
Cette nouvelle fonction de calcul permet de stocker dans une variable, à côté de la classique représentation texte d’un objet (ou tableau) JSON, un réel objet JSON, permettant des traitements nettement (vraiment très très nettement !) plus rapides.
Exemple d’utilisation :
Soit $json contenant du JSON, par exemple un tableau dans lequel nous allons effectuer une boucle (par script ou avec la fonction While / TantQue.
Définir Variable [ $json ; JSONParse ( $json )] retourne une variable $json inchangée quand on l’exploite avec des fonctions texte ou nombre (par exemple : Longueur ( $json ) ou Debut ( $json ; 1 )), mais qui contient également un véritable objet JSON, permettant aux fonctions JSON, notamment JSONGetElement d’agir beaucoup, plus vite.
D’autre part, la fonction JSONParsedState ( $json ) permet de savoir si la variable $json contient un objet/tableau JSON, et si oui de quel type (3 pour objet, 4 pour tableau).
[/vc_column_text][vc_column_text]
Insérer texte : la limite de longueur supprimée
Depuis que la cible de ce pas de script peut être une variable, ce pas de script est de retour en grâce car il permet d’introduire une constante de texte sans utiliser le moteur de calcul, et donc sans échapper les guillemets et autre retours chariot.
Mais la limite de longueur de 30 000 caractères pouvait parfois être un problème. C’est désormais résolu, la limite est désormais de 250 000 000 (deux-cent-cinquante millions). Attention, si vous utilisez le plugin MBS sur mac, pensez à le mettre à jour, de longues variables pourraient le faire planter (c’est de toute façon une bonne idée que de le maintenir à jour).
[/vc_column_text][vc_column_text]
Dossiers dans les fonctions personnalisées
Dans le même genre d’idée, on peut désormais regrouper les fonctions personnalisées par dossiers. Malheureusement, cette nouveauté se fait au détriment de la possibilité – indispensable à mes yeux – de trier les fonctions, soit par ordre alphabétique, soit par ordre de création.
La possibilité nouvelle de rechercher dans les fonctions personnalisées ne vient que très partiellement pallier cet inconvénient.
Plus grave, le fait de créer des dossiers avec la version 2025 (22) rendra la gestion des fonctions impossible avec les versions antérieures. En combinaison avec le fait que la version 2025 ne peut plus cohabiter, sous Windows, avec d’anciennes versions, c’est hautement problématique.
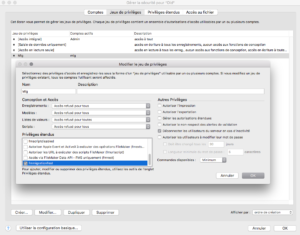
De plus la fenêtre de gestion des fonctions personnalisées semble avoir été faite par un stagiaire, avec des boutons rectangulaires comme on n’en trouvait plus que dans la gestion des modèles – partout ailleurs nous avons des boutons arrondis), mais sans respecter la taille de police ou la marge. (à gauche, la fenêtre de gestion des modèles, à droite celle des fonctions personnalisées)

[/vc_column_text][vc_column_text]
Espace de travail de script : code repliable
On peut désormais plier/déplier des partie de code dans les scripts, notamment à chaque fois qu’un pas de script provoque l’indentation (Si, Sinon, Fin de si, Boucle, Ouvrir transaction…).
Note : à propos d’indentation, le comportement a changé : les pas de script désactivés ne modifient plus l’indentation, facilitant ainsi la lecture d’un script dont certains pas de script on été désactivés.
[/vc_column_text][vc_column_text]
Un SQL plus puissant
De nombreuses améliorations ont été apportées à l’interface SQL utilisée par ODBC ou les plugins. Grâce à la mise à jour de la bibliothèque utilisée, on peut désormais utiliser les intervalles, les clauses IN, ALTER…
On peut donc désormais facilement renommer un champ (par exemple) avec un plugin capable d’exécuter une requête SQL (MBS, BaseElements…) et une requête ALTER.
FETCH NEXT facilitera les systèmes de pagination.
Autre amélioration, dont bénéficie aussi la fonction de calcul ExecuterSQL : on a désormais accès à une nouvelle table système : FileMaker_ValueLists, ainsi, pour les listes non relationnelles, qu’à leurs valeurs FileMaker_ValueList_{NomDeLaListe}
[/vc_column_text][vc_column_text]
Extraire le texte d’un PDF
Une nouvelle fonction de calcul permet d’extraire le texte d’un PDF stocké dans une rubrique conteneur.
Attention, il ne s’agit pas de magie ou d’OCR, simplement de l’extraction de la couche texte du PDF, et c’est déjà très bien.
[/vc_column_text][vc_column_text]
Nouveautés de la gestion de base de données
Cette interface apporte plusieurs nouveauté :
- à l’image de ce qui était possible au niveau des rubriques, il est désormais possible d’ajouter un commentaire au niveau des tables. Chouette !… sauf que Claris a oublié de nous donner la fonction de calcul correspondante !
- le type de résultat des rubriques Calcul est affiché dans la liste des rubriques. Enfin ! Malheureusement l’icône à gauche des rubriques dans l’éditeur de calcul ne distingue pas, elle, les différents types. Mais c’est un bon début !
[/vc_column_text][vc_column_text]
Modèles
Quand on modifie la base de données, les changements sont automatiquement reflétés dans les modèles. On pouvait déjà, dans les réglages de l’application, demander à ce que les nouvelles rubriques ne soient pas ajoutées au modèle courant. On peut désormais faire en sorte qu’aucune modification de la structure de la base de données ne soit reflétée (pas de changement des libellés, pas de création de modèle pour une nouvelle table…)
Mais la grande nouveauté, ou plutôt la petite nouveauté que vous allez adorer, c’est la possibilité d’ajouter des objets à un groupe sans avoir besoin de défaire le groupe (et de perdre les conditions de masquage…). Ceci peut se faire par les menus ou, plus naturellement, grâce à la palette d’objets. Bien sûr l’opération inverse (retirer du groupe) est également possible.
[/vc_column_text][vc_column_text]
Nouveautés pour Windows
Deux nouveautés très importantes à mes yeux pour Windows :
- l’action de script Envoyer courrier en passant par le client de messagerie devrait normalement fonctionner correctement avec tous les clients (Thunderbird…) et non plus seulement avec Outlook (et pour Outlook, on devrait en avoir fini avec les problèmes des versions récentes)
- si l’utilisateur est connecté à son réseau local via Entra ID, le Web Viewer héritera de cette authentification. C’est un grand progrès pour les situation ou une application web interne requiert l’authentification.
[/vc_column_text][vc_column_text]
Nouveautés pour macOS
Il y a énormément à dire sur ce chapitre. Comme dit précédemment, Claris se rapproche de sa maison mère, Apple, et il est important de matérialiser cela par l’expérience utilisateur. Il était anormal que, pour satisfaire l’aspect multi-plateforme de FileMaker, un utilisateur soit perdu en ouvrant FileMaker.
Ainsi, voici les nouveautés remarquables :
- la couleur de surbrillance définie dans les réglages système est désormais appliquées aux dialogues de FileMaker.
- le design des volets gauche (liste de rubriques / objets / add-ons) et droit (inspecteur) est revu complètement. Personnellement, je trouve qu’on passe plus de temps à scroller dans l’inspecteur, mais un peu de fraicheur ne fait pas de mal.
- la vue Tableau dispose de nouvelles options qui permettent un résultat graphiquement beaucoup plus “clean”.

- le centre de lancement est revu. Attention, il n’est pas évident de trouver comment supprimer un favori ou une application récente. Il faut le sélectionner et l’effacer au clavier (Delete)
- enfin et peut-être surtout, la barre d’outils est revue. Nouvelles icônes, nouvelles possibilités de personnalisation de la barre d’outils (chaque élément peut être ajouté/supprimé individuellement…), et fin des couleurs pour le mode modèle.
[/vc_column_text][vc_column_text]
FileMaker Server
Comme dit plus haut, le gros des nouveautés concerne l’IA (recherche sémantique sur serveur, RAG, exécution de modèles en local…)
De grandes améliorations ont été apportées à OData, notamment les fonctions d’agrégation (y compris AS). On peut donc contrôler pleinement la forme de la réponse, par exemple en concaténant le nom et le prénom et en renommant (AS) “nomComplet”. Pour l’instant, ces fonctions ne s’appliquent à la partie $select de la requête et non à la partie $filter (équivalent de WHERE en SQL). Cela reste pour moi la principale raison de continuer à utiliser ODBC, mais espérons qu’une version ultérieure apporte cette amélioration.
D’autre part, les problèmes avec les caractères spéciaux introduits en version 21 ont été réglés.
Attention toutefois, une modification importante dans la manière de retourner le ROWID vous obligera à adapter votre code pour parser cet élément. J’avoue mon étonnement concernant ce choix.
Il est désormais très facile d’installer et de mettre à jour un certificat SSL Let’s Encrypt (ce que fmcloud.fm fait pour vous depuis “toujours”).
On peut maintenant définir la page d’accueil de Web Direct depuis la console d’administration ainsi que depuis l’admin API.
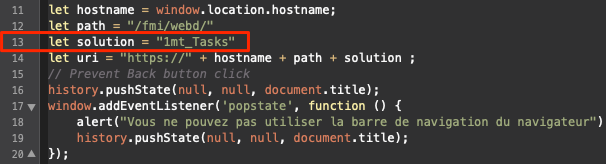
Web Direct : une alerte prévient l’utilisateur qu’il va quitter l’application quand il clique sur le bouton Back (retour) de son navigateur. Enfin la fin de cette technique de Romain Dunand et Ceydrick Valentini.
On peut, depuis FileMaker Pro, désactiver pour Web Direct le menu local sur une rubrique conteneur.
Voici pour un premier tour. J’espère vous avoir fait gagner du temps pour appréhender cette nouvelle version. N’hésitez pas à commenter ci-dessous.
[/vc_column_text][/vc_column][/vc_row]


 Depuis toujours, deux événements se distinguent dans la manière de modifier des données : le drag and drop et
Depuis toujours, deux événements se distinguent dans la manière de modifier des données : le drag and drop et 


 sur Windows : c’est LA grosse nouveauté : le moteur de rendu des web viewers a été remplacé ! Enfin Internet Explorer 11 est abandonné au profit de Edge (Chromium). En termes de performances c’est le jour et la nuit, et surtout en termes de codage : on peut enfin utiliser un code propre pour afficher des contenus complexes ou simplement “modernes”.
sur Windows : c’est LA grosse nouveauté : le moteur de rendu des web viewers a été remplacé ! Enfin Internet Explorer 11 est abandonné au profit de Edge (Chromium). En termes de performances c’est le jour et la nuit, et surtout en termes de codage : on peut enfin utiliser un code propre pour afficher des contenus complexes ou simplement “modernes”.











 To make a long story short, the application is about booking management and all the customer support that goes with it.
To make a long story short, the application is about booking management and all the customer support that goes with it.