[vc_row bg_color=””][vc_column][vc_column_text]Last June at dotfmp 2018 in Berlin, we had the great honnor to welcome an esteemed Californian member of the FileMaker developer community, Kevin Frank (@FileMakerHacks)
Besides being a long time friend -I remember the old times when participating in our ‘Friday Night Chat’ at 3AM CET wasn’t an issue for my young, fast-recovering body- he’s always been and still is one of the most talented and clever writers on the topic of FileMaker. I love (I somehow share, I hope) his kind of scientific approach to FileMaker, and his blog FileMaker Hacks is an endless source of information and inspiration.
At dotfmp, he presented two sessions in a row about virtual lists. I’m not going to repeat everything he said there because some of it is available on FileMaker Hacks already, and I wouldn’t pretend here to be able to fill the gap between what can be read there and what you perceive while listening to someone in person.
But the magic at dotfmp is that it is an unconference. And the schedule evolves all the time, so a session can be extended in another, or a discussion can be scheduled almost on the spot and everyone notified, thanks to the great web tools Egbert Friedrich (@dotfmp) and Andries Heylen (@AndriesHeylen) have put together.
Kevin’s virtual list sessions made me think I should show something on the subject, so Laurent Spielmann (@laurent_at_joes) and I pushed a new session to the calendar, and here it goes (thanks to Heidi, room moderator and keeper of the keys 😉 )
Laurent and I have spent a large part of our time during the two last years working on a big project. The application manages tens of gigabytes, super intensive activity (24/7, 120 users), constant imports from various data sources, 4 servers, 40 files… a beast.
Why a virtual list?
 To make a long story short, the application is about booking management and all the customer support that goes with it.
To make a long story short, the application is about booking management and all the customer support that goes with it.
In the main interface used by the greater part of users, there’s a portal showing all the interactions with the customers, providers…
There is a lot of different things in there: incoming and outgoing e-mail, sms, notes, internal messages… a lot. Each is also displaying data more that 1 table occurrence away (user, department…)
Because FileMaker portals (and list views) can only represent records, as opposed to a result of a query on various tables (union), we would usually tend to denormalize data and store all these different things in the same table. But with such an amount of data, this would be unimaginable. Not only is the data split accross multiple tables, but also accross multiple files.
As a result, a virtual list is a good option for the UI.
Previous situation
In fact, the solution we had designed in the first place was not really a virtual list. It was a somehow-but-not-really-virtual list. For each record in one of the data tables, we would create a record with a minimal amount of data in a UI table. Basically, it contained the booking ID (booking being the main record from which we need to see the related data), and the UID of the related record.
All the rest (displayed data, tooltips, data used in conditional formatting…) was obtained using unstored calculations. So a record of our interface table could display information coming from an inconming e-mail, an outgoing sms and so on.
So in a way, this list was virtual because the data it displayed was not stored in its table but using unstored calculations. But on the other side it wasn’t virtual because the records really existed. A booking record had n related records in the view table.
After a year and a half of production, this almost empty table was about 13 gigabytes (most of which was index). We had to do something.

Why not a really virtual list?
At this point, you might wonder why we hadn’t chosen a truly virtual list.
There are two reasons that combine.
- avoid data transfert over the network. An approach of the virtual list is to get all the required data in one or more global fields, and then parse it in different fields or repetitions using unstored calculations. In this application, it is common to load a record of which you see only a few related records, without scrolling to see all related data. Therefore there is no need to download all the data into a global field. With 120 users on the network, downloading so much unnecessary data would have been a problem. So we knew that even if we would go for a virtual list (every user would look at the same records, but each record would display something different, depending on which booking is loaded), the data would have to be unstored and related (i.e. data for an incoming e-mail would still reside in the incoming e-mail table)
- given 1, the number of users also has an impact on the unstored calculations. If 120 users are looking at the same records (but viewing different related data), experience tells us an application becomes sluggish. This would not be the case if the data was not related but entirely in the virtual list. But as explained above, it was not possible in our case.
And suddenly came… FileMaker 16
Just when we needed to tackle this file size issue, FileMaker 16 was released. And with it the solution to our problem.
The feature that helped us is the ability to define an External FileMaker Data Source as a variable. To me, it’s the most important change in recent years. It widens the horizon tremendously, with all sorts of uses and contexts.
In this instance, we used it to eliminate the ‘too many users issue’ by loading the virtual list on each client.
Here are the steps that we took:
Change in the data model
This steps doesn’t apply to most situations. It was necessary in ours, but I could write another blog post just on it.
In the previous situation we had millions of records with basically foreign keys (one for the booking, one for each source of related data). The rest was all unstored calculated fields.
We wanted to get rid of them and have only one record per booking with all the required information. We could even have added this to the booking table, but the plan was NOT to make this table heavier (and there are plenty of other reasons why we wouldn’t do that, but they’re off topic).
So we went for a CLOB-like approach. In our new table, we had of course the booking ID (foreign key), and another text field in which we needed to store everything we need for the virtual list.
So say that each row of our portal had a id_user, potentially some keys among: id_provider, id_customer, id_incomingEmail, id_outgoingEmail, id_incomingSMS…
We defined a format, using pipe as separator “|” for fields (which makes it a not-a-CLOB, one could argue), and ¶ for records.
So for 1 booking we could have
|user345|||outSMS||
||||inEmail2048|||
…
and so on. So each row of the future portal would have to look up to 1 line only.
This is off topic, but once we agreed on the format, we wrote a script to transform our existing data into this new.
The first time we ran it and measured performance, we concluded that a fast computer would need about 9 months to process all.
So we tried to optimise. The time fell to 4 months. Better. Not good enough. We were not in an emergency, but I can’t let a computer working for 4 months just to transform some data. No way. No, no, no.
Then I asked the community. What language would you use to do this? I had the intuition that Python was a good option. Indeed, several people suggested it to me. That was reassuring.
But two developers that I value immensely, David Wikstrom (@CamelCasedata) and Clément Hoffmann raised their hands and said “R”.
David wrote a small application in R, and it took exactly 8 minutes to do the job FileMaker was doing in 4 months. So just to say: never let the system beat you. There’s always a way.
So now instead of having between 1 and 250 records for each booking in the old view table, we have exactly one.
Of course, this change in the data model had immediate impact: we also needed to modify the processes that used to create/edit/delete records. Now it should only work in this single record (add a line, remove a line, edit a line). But this was quite trivial.

The Local File
Thank you for reading this all the way, but so far there is really nothing about a ‘Client Side Virtual List’, and this blog entry looks more and more like some link bait.
Don’t worry, here it comes.
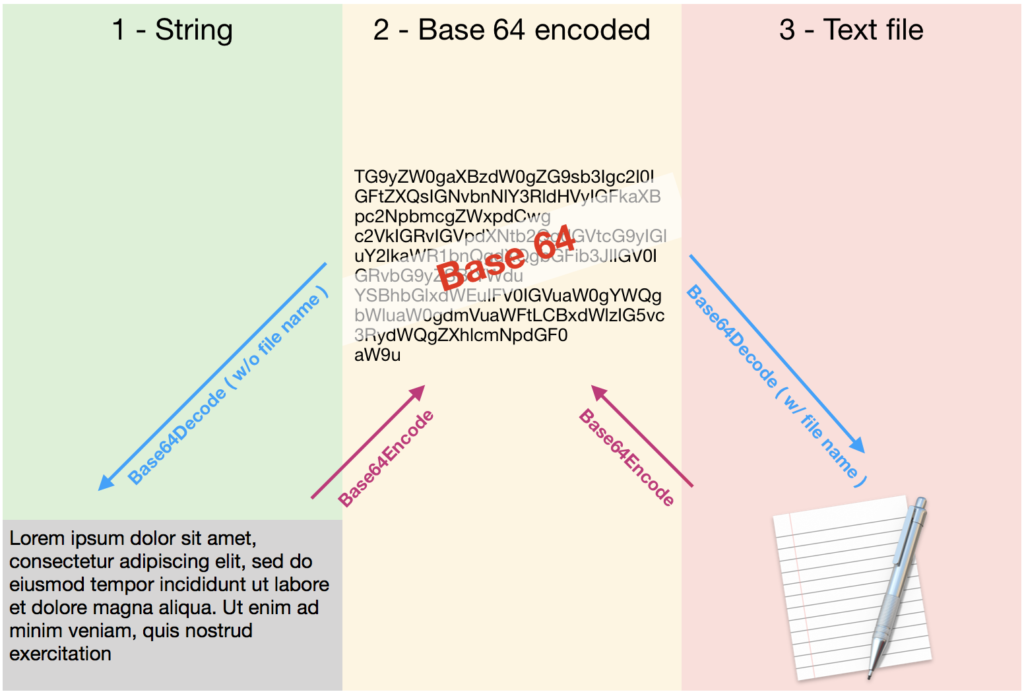
We created a new file that was to be open (hidden) by the client. It has references to all hosted files it needs to get its data from or resolve unstored calculations. The external references point to the server with an absolute path. (fmnet:/<server>/<filename>)
As the file will not contain any other data than IDs, we went for a very straight forward security policy with a auto-login defined in the file options.
The file (Localfile.fmp12), with no data at all was then inserted in a container of the Settings table (a single record table) of the main file.
Since FileMaker 16, you can define a FileMaker External Data Source using a variable, meaning that each user for instance can have his own source.
So we defined in the main file (the one with the portal), a variable data source pointing to the client temporary folder, followed by the local file name.
Note: you need to do this before any call to that datasource is made, even implicitely. Namely, it means that not only should you declare this variable in your startup script, but also you can’t have any reference to the external source in the startup script, because at runtime, FileMaker will resolve all external references when the script begins. Any call to this external source should happen in a subscript.
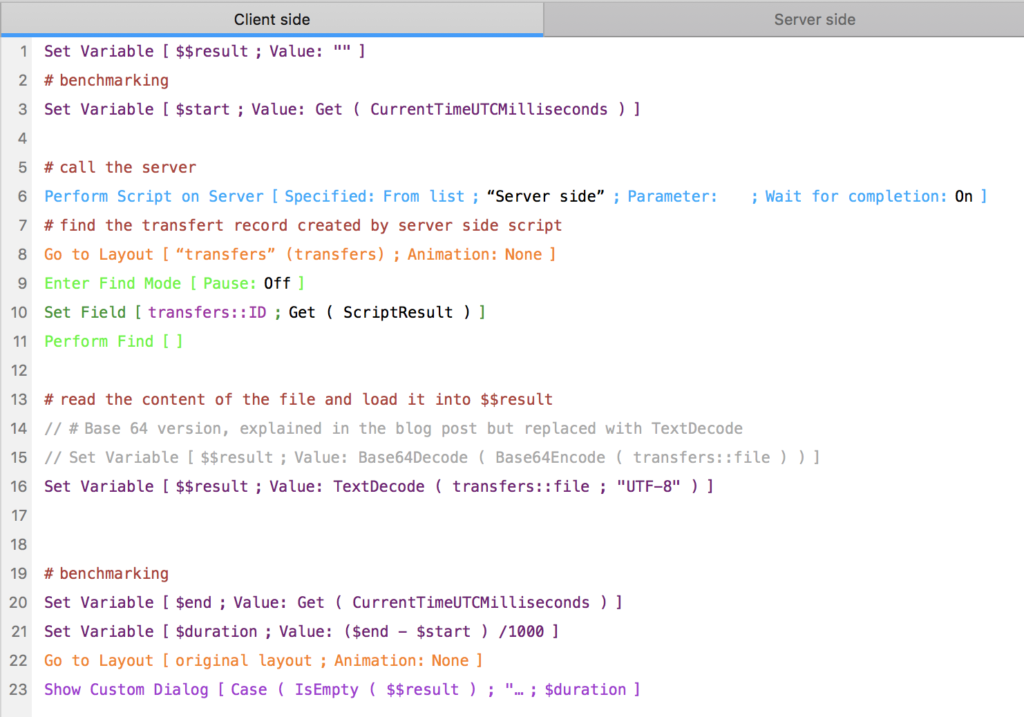
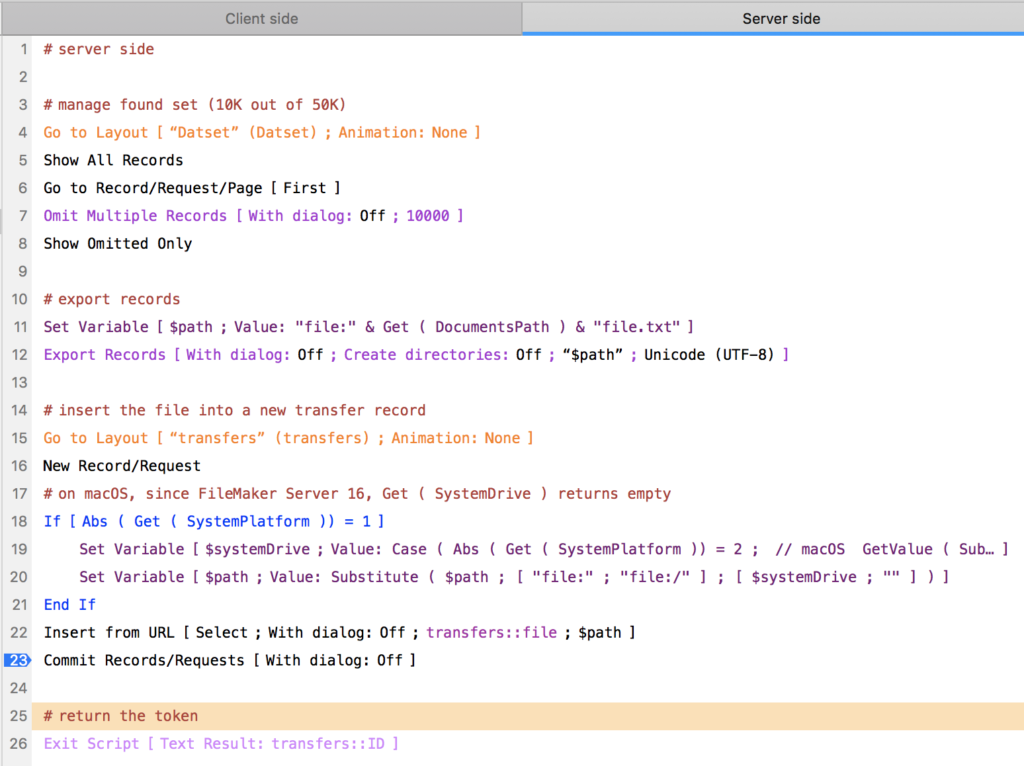
Startup script
- Startup script begins
- A variable is declared: Set Variable [ $$localPath ; Get ( TemporaryPath ) & “Localfile.fmp12”]
- Perform script [ Install local file ]
- Do other things without any reference to the local file, otherwise the existence of the other file will be resolved in 1. With no chance to declare a variable (2.), and therefore leading to a ‘file missing’ situation.
Subscript (Install local file)
- Go to layout [ Settings ]
- Export Field Contents [ containerField ; $$localPath ] // the container field contains the client side file.
That’s it! Now all we have to do is to load the virtual list. For this we use a simple lookup.
Then a loop creates as many records as we need to display. And we can delete them on next run (remember it runs locally, there is no impact on other users because they’re working on their own file). The load script is triggered onRecordLoad on the main file.
An optimisation we made was to split the virtual list into several (1 per ‘column’) before we create the records. This made the system even faster.[/vc_column_text][/vc_column][/vc_row][vc_row color=”color7″ text_color=”color4″ global_atts=”yes” style=”padding-x: 5px; padding-top: 25px; align: center; ” bg_color=””][vc_column width=”1/4″][ish_icon icon=”icon-download” align=”center”][/vc_column][vc_column width=”3/4″][vc_column_text global_atts=”yes” css_class=”btn btn-primary”]Download a sample file here. ClientSideVirtualList.zip
Please share if you liked this post.[/vc_column_text][/vc_column][/vc_row][vc_row bg_color=””][vc_column width=”1/1″][vc_row_inner][vc_column_inner width=”1/1″][/vc_column_inner][/vc_row_inner][/vc_column][/vc_row]