Parfois, un leader ne peut se contenter de ce qui est simplement à disposition. En tant que 1-more-thing, leader mondial dans l’intégration FileMaker/Tableau, nous avons ressenti le besoin de développer notre propre connecteur.
Aujourd’hui, nous avons le plaisir de vous annoncer la mise à disposition gratuite et en Open Source de notre connecteur FileMaker pour Tableau : filemaker2tableau !
Ce connecteur se base sur la dernière version du Web Data Connector (WDC) de Tableau et bénéficie d’une interface simple et intuitive pour relier vos données FileMaker avec vos tableaux de bord Tableau Software. vous gagnerez ainsi du temps dans la phase de préparation de vos sources de données.
Les avantages en comparaison du connecteur natif fourni par Claris sont nombreux :
Auto-complétion de la liste des bases de données
Auto-complétion de la liste des modèles disponibles dans un fichier
Connexion “multi-table” : connectez plusieurs modèles à la fois pour tout importer en une fois !
Accédez au connecteur dans Tableau en utilisant l’adresse de votre serveur et le nom du dossier dans lequel le connecteur a été installé (ex: https://mon.filemaker.server/fm2tableau)
Notes importantes :
Le connecteur doit être installé sur le serveur FileMaker qui publie les données (restrictions CORS)
L’authentification oAuth n’est pas encore supportée (mais ça va venir)
Les prérequis sont les même que pour le connecteur natif de FileMaker Server (dataAPI activé sur le serveur et comptes avec le privilège fmrest activé pour l’accès aux données)
Dans la foulée, nous avons reçu le “grade” de Claris Connect Partner de la part de Claris International, qui atteste du fait que nous avons suivi les formations correspondantes et sommes capables de vous conseiller efficacement sur les plans techniques et commerciaux à propos de la plateforme Claris Connect.
Marketplace
Mais les bonnes nouvelles ne venant jamais seules, deux de nos produits occupent les deux premières place du FileMaker Marketplace mondial !
#1 : Nutshell Console est un outil qui s’installe sur un serveur FileMaker et permet d’une part de configurer et d’administrer facilement certains aspects de FileMaker Server inaccessibles par la console d’administration standard, mais d’autre part, et surtout, Nutshell Console permet de tirer des statistiques, de monitorer l’activité du serveur et de détecter facilement les causes d’un problème ou d’un ralentissement.
#2 : FM Audit Log 2.0 est une solution native FileMaker que les développeurs peuvent implémenter dans leurs applications afin de garder une trace de toutes les modifications de données. Compatible avec FileMaker Pro, FileMaker Go et FileMaker Web Direct, FM AuditLog Pro 2.0 permet également de revenir en arrière (roll-back)
Lors de la DevCon 2020, Brad Freitag (@bradfreitag), CEO de Claris International, annonçait le rachat par Apple/Claris de la startup italienne Stamplay.
Quelques mois plus tard, Claris Connect est né ! Cette plateforme permet de créer et d’automatiser des flux de données très complexes en quelques instants seulement… et sans compétence technologique particulière.
Ce qui demandait il y a encore peu des jours de développement pour intégrer différents services web peut désormais se faire très facilement, en incluant de la logique, de la gestion d’erreur, des transformations…
Mais pour mieux comprendre, le mieux est sans doute encore de regarder cette vidéo de présentation en français, par Romain Dunand (@airmoi).
Dans cet exemple, nous intégrerons un site sous WordPress avec le plugin Woocommerce, FileMaker Server et Office 365. Notez que Claris Connect est tout à fait indépendant du logiciel FileMaker, qui n’est utilisé ici qu’à titre d’exemple.
C’est aujourd’hui que Claris lance son FileMaker Marketplace. Et devinez qui a les honneurs de la première page ?
Nutshell Console bien sûr ! Le produit phare de la saison, cité à de nombreuses reprises lors de la dernière DevCon à Orlando.
Mais au-delà de cette petite satisfaction, nous sommes très enthousiastes à l’idée de ce FileMaker Marketplace. Pour l’instant, le contenu est encore limité quoiqu’on y trouve déjà de bons contenus (apps, formation…), mais nous sommes surtout convaincus qu’à terme il contribuera à offrir à la plateforme une visibilité incomparable à celle qu’elle connaît aujourd’hui.
Nous avons même quelques projets qui pourraient intéresser les développeurs. Si cela vous intéresse, n’hésitez pas à prendre contact avec nous ou à nous rencontrer lors des conférences européennes à venir (défilez en bas de la page pour les conférences européennes)
[vc_row bg_color=””][vc_column][vc_column_text]Comme à chaque année, la dotfmp unconference a eu lieu à Berlin la semaine dernière et, comme à chaque année, ce fut le meilleur événement FileMaker pour les geeks.
Merci beaucoup, Egbert, d’avoir fait en sorte que cet événement soit si intéressant et plaisant.
Nous avons bien sûr vu beaucoup de bonnes séances et assisté à de nombreuses discussions ouvertes, parmi lesquelles je citerais certaines de celles que j’ai considérées comme révélatrices:
Heidi Moyer concernant Tableau et Python
Charles Delfs à propos des tests d’interface utilisateur
Et bien sûr, nous en avons présenté quelques unes :
La chose la plus cool que vous ayez faite cette année: une discussion ouverte au tout début de la conférence. De nombreuses personnes ont partagé une excellente expérience et des idées au cours de cette session. C’était vraiment cool (je pense).
Discussion ouverte sur la validation des données. C’était une session complètement improvisée faisant suite à une discussion qui s’était déroulée lors d’une autre “Open Cowboy Session”, organisée la veille par Mads Chirstensen. Et encore une fois, la forme «non préparée» et ouverte de cette session l’a rendue très interactive et intéressante. Ian Jempson m’a envoyé ce précieux feedback ce matin :
Also wanted to say that your session on data validation has proved helpful for me this morning as I get back to work. One of our tables has had the business rules change so many times over the years that the older records won’t validate anymore, so I’ve been doing a bit of refactoring of validations and going back to basics has simplified things nicely. Thanks for hosting so many great talks!
Andries a organisé une session sur les implémentations de OAuth. Il a montré comment il avait réussi à tweeter directement à partir de FileMaker en utilisant OAuth.
«Bien que Kevin ne soit pas là» : Kevin Frank n’a malheureusement pas pu se rendre à Berlin cette année, mais il avait préparé une session sur les nouvelles fonctions FileMaker 18 «While»et «SetRecursion». Nous avons donc convenu que je prendrais la relève et que je serais sa voix à Berlin. Alors oui, Kevin! vous étiez un berlinois.
J’ai présenté ces deux fonctions, mais aussi touché à la récursivité en général dans FileMaker. Il y avait beaucoup à dire après tout. Et merci, Paul Jansen, pour cette idée fantastique!
Andries Heylen a ensuite présenté une session superbe et dense sur les Webhooks et les API. Il a réussi à clarifier un grand nombre de concepts différents.
Enfin, j’ai organisé une sorte de jam session de clôture. J’imagine que c’est ainsi que vous appelez la dernière session planifiée, alors que tout le monde boit déjà de la bière ;-). C’était l’occasion de présenter Nutshell Console avec son principal développeur, Yann Trauchessec. Si je peux en juger par le ratio participants/ventes, je pense que le produit s’est révélé attrayant! merci à tous les acheteurs, j’espère que vous l’apprécierez autant que moi. Oh! au fait, voici la demande de fonctionnalité sur Community que j’essayais d’expliquer. S’il vous plaît la soutenir si vous l’avez aimé.
Enfin, je tiens également à dire qu’il est si fantastique de trouver des personnes pouvant être fascinées par de beaux codes tels que les fonctions d’Agnès Barouh ou Tic-Tac-Toe de Shaun Flisakowsky. Quel plaisir de partager cette passion pour la beauté :)[/vc_column_text][/vc_column][/vc_row]
Aux bords du lac de Paladru (Isère) on trouve d’autres trésors que ceux laissés par les chevaliers paysans de l’an mil… On y dégote par exemple des développeurs FileMaker chevronnés !
En cette fin d’année 2018, nous sommes ravis d’accueillir dans l’équipe de 1-more-thing Yann Trauchessec, un développeur multi-langage avec comme prédilection celui de FileMaker.
Navigant dans l’univers Apple et FileMaker depuis plus de 10 ans. Yann a occupé différents postes clés lui permettant d’avoir une vision d’ensemble tant comme utilisateur, que comme développeur. Son sens aigu et raffiné de l’interface vous séduira… (ce qui semble être fréquent quand on s’appelle Yann dans cette communauté)
“Ce que je cherche c’est de concevoir des applications faciles à utiliser, avec un design abouti et recherché, permettant d’optimiser le temps de chaque utilisateur en apportant une réelle valeur ajoutée aux fonctionnalités développées. C’est dans ce but que je mets un point d’honneur à être en perpétuelle recherche de la meilleure ergonomie possible, en dissimulant la complexité d’une application derrière une interface simple et intuitive. En pensant en priorité à l’utilisateur final.”
One of the most important features of FileMaker 17 is the “current found set portal”. It makes it easy and fast to display the list of found records on the layout (Master/Detail).
Not only does it display them, but it allows to browse records with a single click, without having to write a script or add a button.
Besides, it reflects the sort order, which means you can now design a real Master/Detail view.
In this demo file, I’ll show you a few tips, among which:
how to use the new Get ( ActiveRecordNumber ) function to highlight the current record in the portal
use the found set portal to browse records, and a simple button bar to act as a sortable column header
But also, on a second layout called Detail / Master, you will see what happens if we inverse the perspective and use the current found set portal as the main item of the layout body. We can suddenly use ‘list views’ on a form layout. Benefits:
avoid the annoying “No record message” of FileMaker list view when user clicks on the body
edit the record in a form without leaving the list view (right pane)
add an action / navigation bar on the whole list height (left pane)
you can now adjust the window and control its height
There is a missing feature though: no sub summary layout parts.
Please share if you liked this post.[/vc_column_text][/vc_column][/vc_row][vc_row bg_color=””][vc_column width=”1/1″][vc_row_inner][vc_column_inner width=”1/1″][/vc_column_inner][/vc_row_inner][/vc_column][/vc_row]
At recent dotfmp conference in Berlin (did I already mention this is the best FileMaker conference I know?), a developer challenge was orgnised.
The challenge was to find the fastest way to download data from a FileMaker hosted database to a FileMaker Pro Client over the network.
The table had 50K records (10 fields) of which only 10K had to be downloaded.
But the important thing was that data, once on the client, had to be in any structured, workable, searchable form, not necessarily records/fields.
@AndriesHeylen and I came up with a solution that I believe was considered interesting by the audience, so I’ll share it here, not to say that this is the best way or that I would necessarily use it in production, but I think it’s valid and it’s a good opportunity to visit some nice tricks.
I’ll write this post in a kind of story-telling style, because I think the path we followed was as interesting as the solution, if not more.
To rephrase the challenge, here is what needed to be done:
select 10 000 records among 50 000 (any would do)
transform the data stored in a table into something more appropriate for the next steps
make the data transit over the network from the server to the client
‘render’ this data as a structured array, if that was not already the case, depending on what we would do during step 2.
For each of this tasks we had many options in front of us. So because we hadn’t the time to explore them all (oh yes, I forgot to mention that we had approximately 45 minutes to solve this… while eating in a nice Vietnamese restaurant on Kastanienallee)
So our first approach was to brainstorm about each step independently, so we would only see later how our favorite (supposedly fastest) techniques would combine nicely.
Before we begin, let’s mention that there was one ‘obvious’ solution that was doing the whole thing: declaring a variable on the client, using ExecuteSQL function. ExecuteSQL ( "SELECT * FROM Datset FETCH FIRST 10000 ROWS ONLY" ; "#F#" ; "#R#" )
Where #F# is a custom field separator and #R# a record separator.
We didn’t follow that path because… there was no fun, and we still had 44 minutes to go.
For step 1, selecting the records, we thought about 2 different ways:
through the found set
through a query
A SQL query could be used in the context of an ODBC import (Import records from ODBC), but there’s a no go for this: the only output of Import records is… creating/updating records. We knew that this would take too long, so this ‘easy to solve’ first step showed us immediately that our strategy was not perfect.
Before we could brainstorm on each step independently, we needed to exlude ways that we knew for sure would slow down the process.
We identified 3 potential bottlenecks that we wanted to avoid
A – pre-formatting the data on the server using unstored calculation. Even with a simple calc this would be expensive, and it would make the solution not scalabale.
B – parsing data on the client, including creating records: data had to be ready to use or should not need more than a global transformation, not a per record or per field one.
C – sending a long text string over the network: we assumed it would take longer than if the string was encapsulated in a file
Given this, we browsed the 4 steps
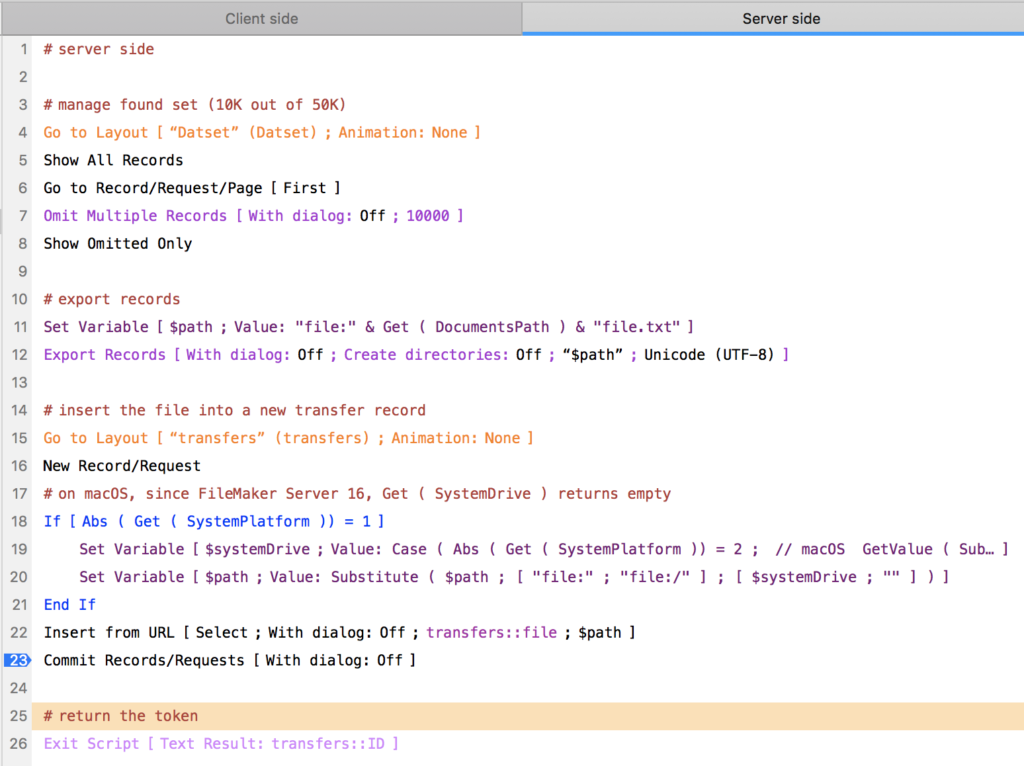
1 – Select the 10K records
To select the 10K records we could only use the foundset since the SQL Query could happen only in Import Records, and we didn’t want to import records (B)
So we would run a script like: Go to layout [ Data ] Show all records
Go to record [ First ]
Omit multiple [ 10000 ]
Show omitted only
2 – Export records
To avoid A and C, we thought the best way was to Export records to a text file (CSV)
This made it clear that the main process (including step 1) should be a server side script because the export would be much faster on the server.
We chose CSV because we believe this is the fastest, but we knew there was a glitch there: the result would not be very easy to use because the flavor of CSV FileMaker uses for its exports, using comas, double quotes and separator for multiline contents is not easy to parse using FileMaker calculation functions (certainly doable, but not easy)
So we thought that if we had time (there was still 25 minutes to go), we would use XML/XSLT instead. It wouldn’t make a big difference in terms of performance.
3 – Make the data transit over the network
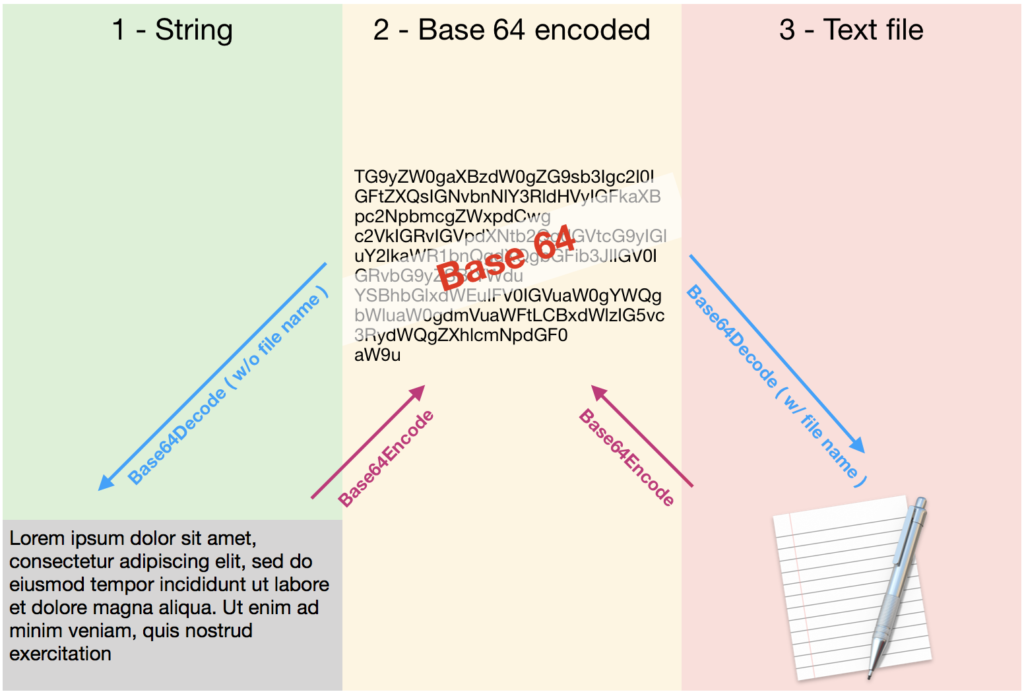
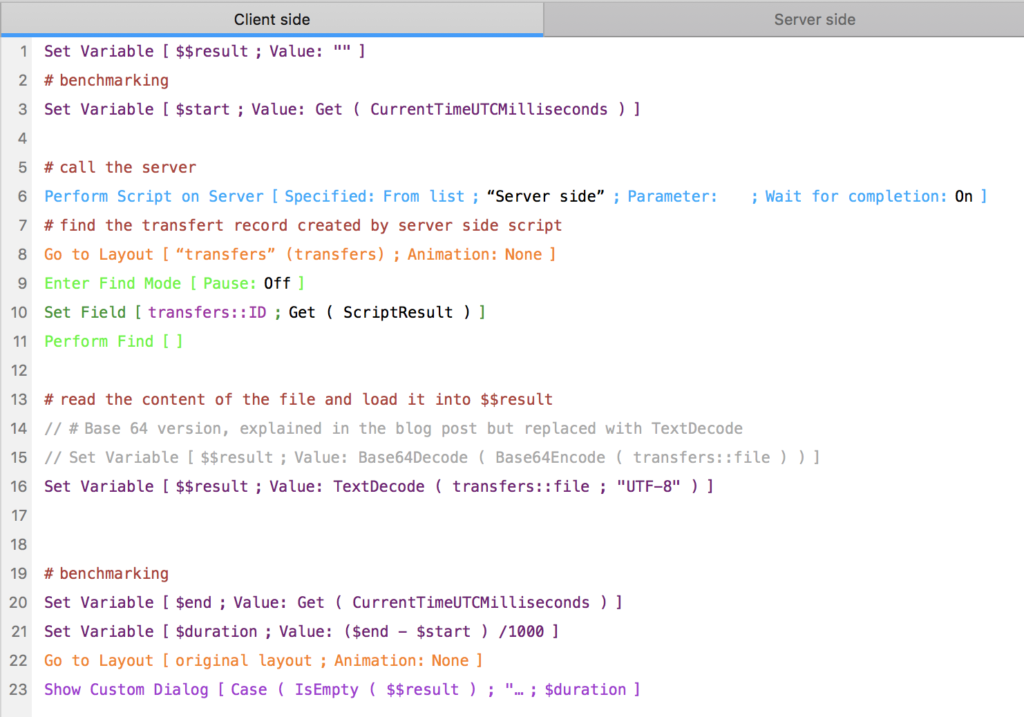
What we know (or think we know, which are two different things) is that sending a long string as a script result would take long. So we wanted to return a text file instead (C). Now that I’m writing this post and that I have much more time, I wonder if we shouldn’t have simply returned the text file as a script result (script results, as script parameters or variables can be of type container). But while on a hurry we went for something different: we created a ‘transfers’ table with a container field and an indexed ID field (serial number)
So after exporting (2) our process:
creates a new record in ‘transfers’
inserts the file into the container (using Insert from URL and the file protocol, because Insert File is not server compatible)
exits the server side script with the ID of the transfer record as a result (token)
the calling (client side) script gets the token using Get ( ScriptResult )
goes to the transfers layout
finds the transfer record
I should mention that inserting a file using insert from URL ate a full 5 minute of our time, therefore ruining our hopes to order desert. This was due to a change in FileMaker 16 that we had forgotten: to convert the path to where we export the records to into a URL from which we can insert the file, we have to remove the system drive. But since version 16, Get ( SystemDrive ) returns empty on FileMaker Server on macOS, so we have to extract it from the Temporary Folder path.
4 – Extract the data into a variable
OK, so now the client has a text file. It’s stored in a container field of the current record, but it could have been available as a script result.
What we now have to do is to read this text file and ‘extract’ its content into a string.
To do this we simply use this not so simple calculation :
Base64Decode ( Base64Encode ( transfers::file ))
In fact we could also use simply TextDecode ( transfers::file ; "UTF-8" ), but it only occurred to me later on. And as a matter of fact, we had several questions about the former expression while presenting our solution, so I’ll try to give a bit of explanation.
Base64 is a encoding algorithm that allows encoding any data. This is very much used to embed binary files in a text, like for example an image in a html e-mail when you don’t want the image visualisation to rely on an internet connection. It is not an encryption method, although a base 64 encoded text is not readable by a human being (that I know, that is to say).
So basically Base64Encode and Base64Decode are two inverse functions, which means that
Base64Decode ( Base64Encode ( "abc")) = "abc"
But it’s not as easy as this and I’ll try to give a clearer explanation that the one I gave when I was asked in Berlin.
In this process, a text can be in 3 different states:
1⃣ a string (data of type text in FileMaker)
2⃣ Base64 encoded text
3⃣ encapsulated in a text file
Base64Encode ( data ) converts a string or a file to a Base64 encoded text depending on the parameter it receives (1⃣➡2⃣ or 3⃣➡2⃣) Base64Decode ( text {; fileNameWithExtension } ) converts a Base64 encoded text to a string (2⃣➡1⃣) or to a file (2⃣➡3⃣) depending on whether you pass a filename or not.
So the two functions are inverse, but on two different operations.
In our example, Base64Encode translates a file into Base64 (3⃣➡2⃣) and Base64Decode translates the base64 encoded string into a string (2⃣➡1⃣).
But again, TextDecode (released with FileMaker 16) is the best option.
That was it, we had 4 minutes left, so just the time to wrap all this in 2 scripts (client side and server side), and add some performance measurement using get ( CurrentTimeUTCMilliseconds ) while paying the restaurant bill, fold the mac and head to the conference room where the solution had to be presented.
Running on a local machine (with FileMaker Server and Pro Advanced on the same computer), the whole process was taking 0.4 seconds. On a local network (WIFI, quite busy and unstable, it took between 0.6 and 0.8 seconds). Not bad.
Please do not hesitate to share your ideas or leave a simple comment below.
Notre approche en tant que développeurs d’applications sur mesure est d’apporter des solutions évolutives à nos clients. Leurs besoins progressent, et ils souhaitent adapter rapidement leur outil à la réalité de leur métier et de leur structure.
Mises à part quelques petites adaptations mineures qui peuvent être “reportées” en direct dans le fichier de production, la plupart du temps, pour pouvoir mettre en oeuvre de nouvelles fonctionnalités, nous devions nous lancer dans une aventure parfois fastidieuse : le versioning.
Ceci est bientôt de l’histoire ancienne
Souvenez-vous de ce à quoi pouvait ressembler un versioning :
Table par table, nous importions les données dans la nouvelle version. En préparation de cet import, il avait fallu régler les correspondances de rubriques entre la table source de production et la table destination du nouveau fichier. L’interface que FileMaker propose pour régler l’import est sans doute le plus indigeste des interfaces de la plateforme : difficulté de positionner les rubriques qui “glissent” de haut en bas, contrôle de correspondance uniquement visuel… cette étape de configuration peut s’avérer gourmande en temps de développement (dans cet article de juin 2010 sur la mise à jour des données, nous revenons sur la méthodologie que nous adoptions dans pareille situation).
Après avoir réglé la séquence d’import, nous devions penser à mettre à jour les éventuels compteurs basés sur des numéros de série.
D’autres couches de l’application contiennent également des données qui avaient pu évoluer et être modifiées par les utilisateurs au cours de leur usage du fichier à mettre à jour :
la sécurité, dans laquelle des comptes ont pu être créés, modifiés, supprimés;
les listes de valeurs personnalisées dont certaines ont pu être adaptées par des utilisateurs disposants des droits pour ce faire.
Vue la complexité et la lenteur du processus de versioning, nous options souvent pour procéder à ces manoeuvres la nuit, le week-end… prévoyant selon le nombre d’enregistrements à transférer de nombreuses heures où avancerait lentement la barre de progression de la fenêtre d’import.
Parfois nous n’avions pas le choix, suite à une corruption de fichier, nous devions repartir d’une clone sain et injecter les données de production, en espérant ne pas interrompre trop longtemps le travail en cours des utilisateurs bloqués.
Un gain de temps considérable
Avec la version 17 de FileMaker, ceci va changer radicalement ! Mais c’est en dehors de l’application qu’il faut aller chercher cette excitante nouveauté. En accompagnement de FileMaker 17 (dans le package de la Developer Subscription), nous trouvons un petit outil léger en ligne de commande…léger mais d’une puissance telle qu’il va nous permettre de revoir fondamentalement le rythme de mise à jour de nos applications.
(On peut s’interroger sur la raison d’une attente si longue dans l’histoire de la plateforme pour bénéficier d’un tel outil – Fabrice se souvient que ses demandes à FileMaker pour un système du genre remontent à plus de 10 ans, et les développeurs étaient nombreux à appuyer dans ce sens.)
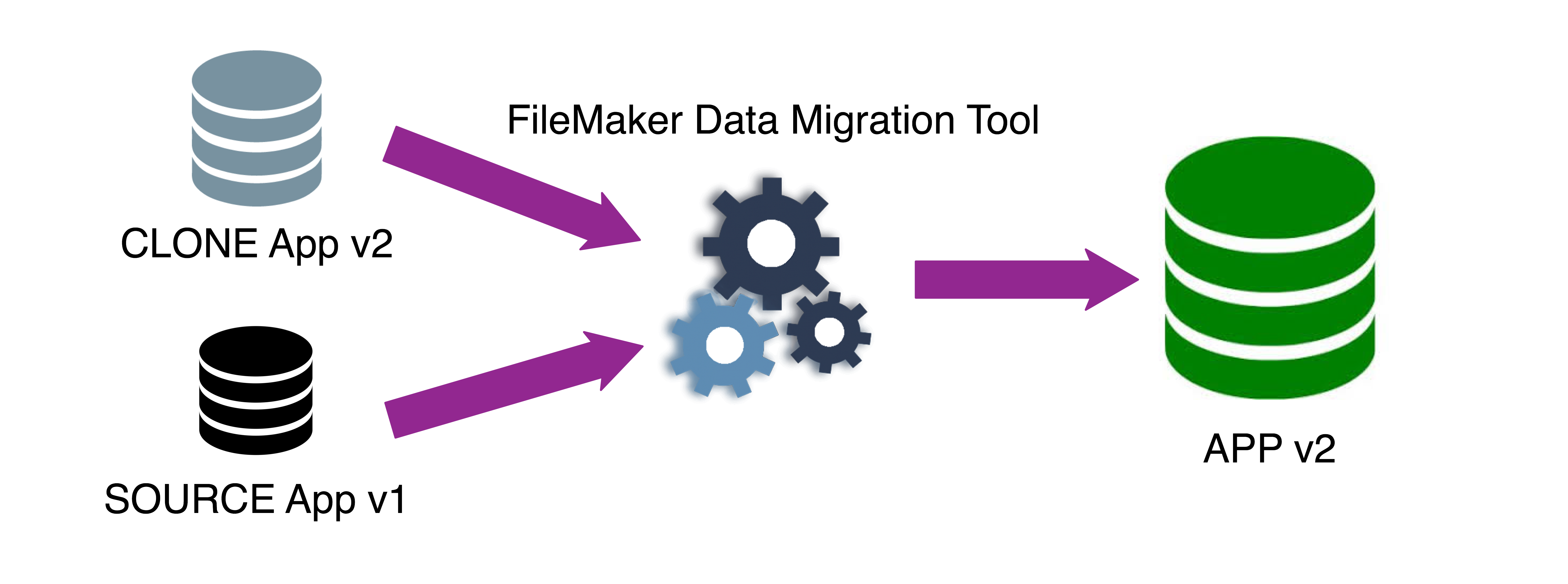
Le DMT, data migration tool, est donc un outil en ligne de commande qui permet d’injecter en un temps record les couches de données d’un fichier source vers un clone de la même base, et ce avec un tout petit minimum de préparation de notre part.
Comme pour le iOS SDK, cet outil vient de le “package” qui accompagne la Developer Subscription (89€HT/an). (Un package qui devient encore plus attractif avec le nouveau modèle de licence…allez jeter un oeil)
Réalisez un clone de la base de données de destination. Précision importante : un clone est une copie du fichier, dénuée des parties données (enregistrements et données locales). Un clone est un clone tant que le fichier n’est pas ouvert. Dès son ouverture, FileMaker y écrit des paramètres locaux (langue, format de date,…) et il perd dès lors son caractère de clone.
en ligne de commande, appeler l’outil FMDataMigration, identifier la source, le clone et la destination
Et c’est réglé ! … un journal affiche la progression, les résultats et erreurs éventuelles.
Un cas vécu : le temps de versionning d’un fichier comportant environ 40 tables et des millions d’enregistrements est passé de 3h00 à 10 minutes !! Et c’est évidement sans compter le temps gagné à ne pas devoir paramétrer la séquence d’importation des données pour chacune des tables.
Au final, nous récupérons non seulement les enregistrements, mais aussi les comptes utilisateurs et les modifications dans les listes de valeurs personnalisées, ainsi que les polices de caractères intégrées au fichier.
Ce qui est transféré
(en fonction des options cfr infra) :
les comptes utilisateurs
les enregistrements
les listes de valeurs personnalisées
le numéro de série suivant des rubriques entrée automatique numéro de série
les index
les ID d’enregistrements
les paramètres régionaux (formats de date, langue par défaut…)
Paramètres de la ligne de commande
(en gras les paramètres obligatoires)
-src_path : le chemin du fichier source
-src_account : un compte accès intégral dans le fichier source (par défaut = Admin)
-src_pwd : le mot de passe du compte (par défaut = vide)
-src_key : l'éventuelle clé d'encryption du fichier source
-clone_path : le chemin du fichier clone
-clone_account : un compte accès intégral dans le fichier clone (par défaut = Admin)
-clone_pwd : le mot de passe du compte (par défaut = vide)
-clone_key : l'éventuelle clé d'encryption du fichier clone
-target_path : le chemin du fichier de destination (par défaut = chemin de la source avec ajout de 'migrated' )
-ignore_valuelists : par défaut le DMT va recopier les valeurs des listes de valeurs personnalisées du fichier source. Ajoutez cette option pour ne garder que les valeurs du fichier clone
-ignore_accounts : par défaut le DMT va recopier les comptes du fichier source ainsi que la clé d'encryption. Ajoutez cette option pour ne garder que les comptes du fichier clone
-ignore_fonts : par défaut le DMT va recopier les polices du fichier source. Ajoutez cette option pour ne garder que les polices du fichier clone
-v : (verbose) mode avec log de progression qui décrit étape par étape ce que le DMT est en train de faire
-q : (quiet) mode silencieux
-force : permet d'écraser un fichier de destination déjà existant
Quelques remarques et points d’attention:
Comment se fait la correspondance ?
Pour la correspondance des tables et rubriques, FM Data Migration Tool procède d’abord par nom et ID identique, puis s’il ne trouve pas par nom identique, puis enfin par ID interne correspondant. Cela signifie par exemple que si vous renommez la rubrique RUBOld en RUBNew et puis que vous créez une rubrique nommée RUBOld, les données de la source contenue dans la rubrique RUBOld seront transférées dans la nouvelle rubrique RUBOld.
Des conteneurs
L’outil est prévu pour que le fichier résultat soit ensuite placé au même endroit qu’à l’origine. Ce point doit être pris en considération dans le cas de stockage externe de conteneurs : l’outil ne gère pas de déplacement ou de conversion de ces fichiers.
Clone tu resteras
Petit rappel : un clone reste un clone tant qu’il n’a pas été ouvert !
Réparation du code ?
Le DMT n’est pas un outil de réparation. Si on a dans la source une donnée corrompue, elle le restera après versioning.
Attention plug-in
Lors du versioning, le DMT “réévalue” les valeurs des rubriques calculs stockées. Ceci peut poser un gros problème si ces calculs font appel à des fonctions issues de plug-in. Le DMT n’ayant pas accès aux plug-in, les résultats de ces calculs sera un ? dans tous les enregistrements. Il faudra par la suite évaluer à nouveau ces calculs en entrant dans la définition de la base de données et en éditant la formule de calcul (y ajouter un espace suffit).
Sécurité : login et mot de passe
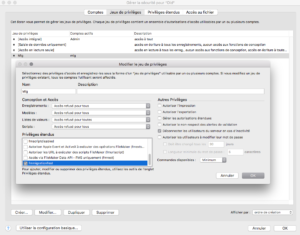
Dans les instructions en ligne de commande, il faut passer en clair un login et mot de passe du fichier clone et du fichier source. Ce login et mot de passe peut être soit celui d’un compte disposant de l’accès intégral au fichier…dans ce cas, vous exposez aux regards indiscrets et laissez dans l’historique du terminal un mot de passe critique. Soit vous pouvez mentionner un compte et mot de passe qui est associé à un jeu de privilège qui dispose d’un privilège étendu dont le nom commence par “fmmigration”. Le nom du privilège étendu doit être rigoureusement le même dans le fichier source et dans le clone (sensible à la casse). Le jeu de privilège ne doit disposer d’aucun droit particulier dans la base de données (ni lecture des données, ni accès aux modèles, scripts,…). C’est sans aucun doute la manière la plus sûre de gérer cet aspect sécurité lors de l’usage du DMT.
Dans l’exemple ci-dessous. Nous avons créé un compte “mig” dont le mot de passe est “123456”; ce compte est associé au jeu de privilège “Mig” qui n’a aucun droit de lecture, d’accès au modèle, scripts,..dans la base. Ce jeu de privilège dispose d’un privilège étendu dont le nom commence par fmmigration : “fmmigrationTest”.
Parmi les changements liés aux nouvelles licences FileMaker, il y a une petite chose à laquelle vous devez faire attention.
Si vous avez un contrat de licence annuel ou sous maintenance, vous avez déjà dû recevoir un e-mail de la part de FileMaker dont le sujet est :
“Plateforme FileMaker 17 – Disponibilité de la version avec maintenance”
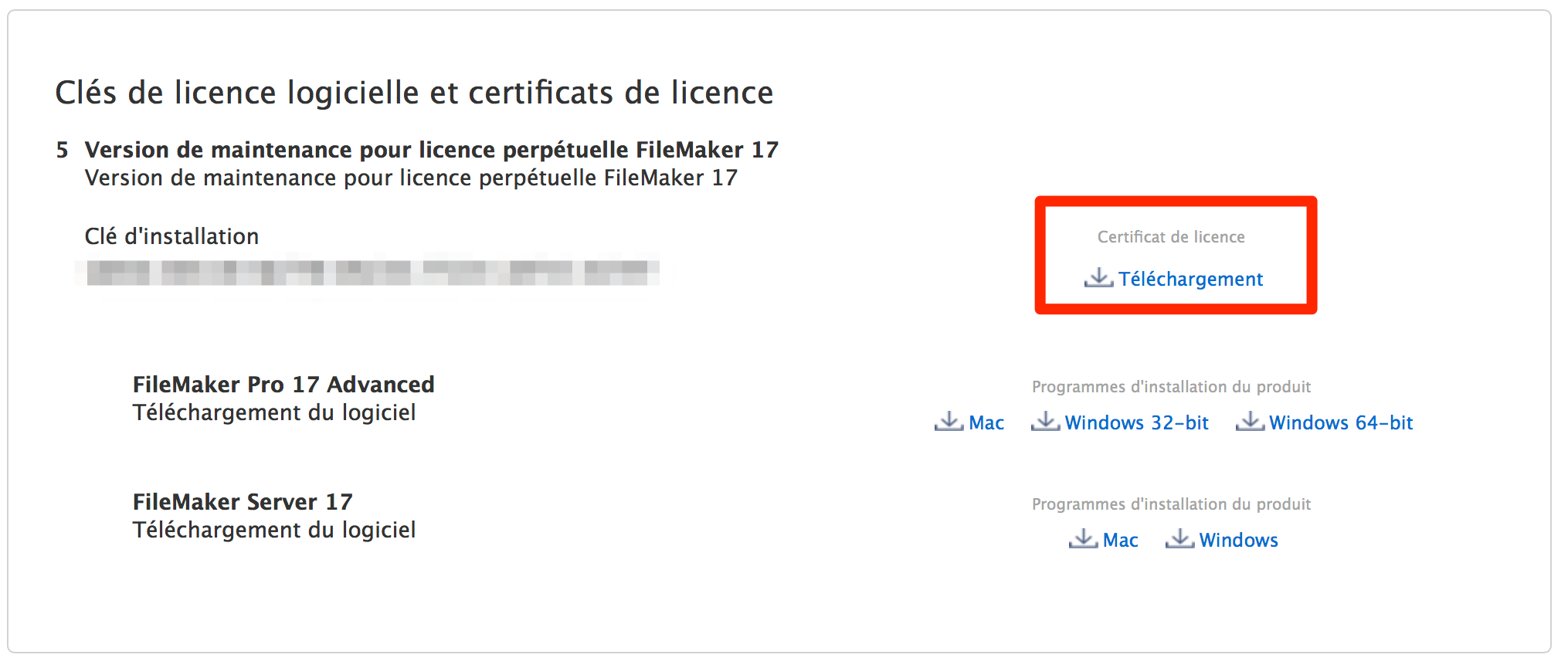
Comme chaque année, il vous permet d’accéder aux liens de téléchargement de la nouvelle version pour une période de 30 jours, ainsi qu’à votre nouvelle clef de licence. (Celle-ci, c’est une nouveauté appréciable, ne devrait plus changer à l’avenir.)
Mais attention ! il y a une nouveauté à télécharger : le certificat de licence de FileMaker Server. Or si passé les 30 jours il est toujours possible de retrouver un installateur de FileMaker Pro Advanced ou FileMaker Server en téléchargeant une version démo, il n’est en revanche pas possible de retrouver ce certificat de licence, sinon bien sûr en appelant le service technique.
Téléchargez-le et conservez-le donc bien !
Pour rappel, si vous passez par notre intermédiaire pour acheter/louer vos licences, vous bénéficiez d’un service de récupération rapide de votre clef de licence*… à condition de nous informer de celle-ci. N’oubliez donc pas de nous communiquer votre nouvelle clef.
*pour cela, il suffit d’écrire à malicence@1-more-thing.com depuis une adresse e-mail référencée.
[Mise à jour : à cause de 22 personnes dont 11 belges courant après un ballon, la date est reculée de deux jours Pendant un Uruguay-Arabie Saoudite]
La nouvelle version de FileMaker vient de sortir, avec son lot de nouveautés, son nouveau modèle de licences, et de bonnes pistes pour entrevoir la direction prise par la plateforme.
Venez découvrir ces nouveautés autour d’un verre le 18 20 juin 2018 à 17:00, avenue de la Couronne 382, 1050 Bruxelles.
Merci de vous inscrire ci-dessous.
[contact-form-7 id=”12958″ title=”Inscription à Présentation FM 17″]
Parce que nous aimons les données. Parce que la science moderne repose sur les données. Parce que nous avons besoin de la science comme la science a besoin de nous… et parce qu’on aime aussi bien rigoler…
1-more-thing sponsorise les 10km de l’ULB (Université Libre de Bruxelles), au profit de la recherche scientifique.
Pour le retour des beaux jours, si vous souhaitez passer un petit moment sympathique entre amis ou en famille (départ de la course des enfants à 9h30, départ adultes 10h30)
Rejoignez notre équipe gratuitement (dans la limite des places disponibles). Inscrivez-vous simplement ci-dessous, nous reprendrons contact avec vous.
Attention, 10km, c’est long. Le sport demande un peu de pratique. Entraînez-vous avant le 22 !
Mise à jour (22/4/18). C’était aujourd’hui. On a bien rigolé, et bien fait avancer la science 🙂
[vc_row bg_color=””][vc_column][vc_column_text]Jeudi 1/3, c’était la fête dans nos locaux bruxellois, pour célébrer la prochaine entrée en vigueur le 25 mai prochain, du RGPD, le nouveau Règlement Général sur la Protection des Données.
Fêter de nouvelles contraintes réglementaires imposées par l’Europe, voilà qui est pour le moins singulier, non ?
Si nous avions choisi de donner un côté festif à l’événement, c’est parce que nous pensons, en tant que citoyens européens, que c’est une bonne chose de disposer d’un cadre juridique pour protéger nos données personnelles de l’appétit de certains pour qui la quantité de données collectées prévaut souvent sur le droit de chacun au respect de sa vie privée.
Par ailleurs nous considérons que cette obligation peut être vue comme une belle opportunité.
L’opportunité d’une part de se repencher sur la manière dont vous traitez, stockez, et même protégez les données personnelles dans les applications que nous développons pour vous.
D’autre part, une opportunité de profiter de l’occasion pour réexaminer nos procédures et vérifier si elles sont bien en conformité avec les principes définis par le RGPD.
À 18 heures donc, nos valeureux clients et invités, défiant le froid, la neige et les embouteillages, sont venus se réchauffer chez nous, et surtout s’informer sur cette nouvelle réglementation européenne. Florence de Villenfagne, consultante ICTLex et formatrice au Data Protection Institute, était notre invitée et a exposé le cadre juridique du RGPD ainsi que les principales implications.
Sa présentation a été particulièrement appréciée. Elle avait pris le temps de s’enquérir des activités de chacun avant son intervention, et a pu ainsi proposer des exemples précis et très parlant.
Tanguy Collès, désormais “certifié” DPO par le Data Protection Institute a ensuite pris la parole et a présenté les différents axes selon lesquels 1-more-thing évoluait afin de proposer le meilleur conseil possible à nos clients autour du RGPD.
Il a abordé les aspects contractuels, juridiques, organisationnels et techniques. Nous avons vu que de grandes parties du RGPD était déjà présentes dans les règlementation antérieures, et que 1-more-thing avait déjà une bonne culture de la protection des données. Mais nous avons aussi vu qu’il fallait prendre un certain nombre de mesures -techniques et non techniques- pour se mettre en conformité.
Après une session de questions/réponses, nous nous sommes déplacés dans l’open space, avons un peu poussé les bureaux, et donné corps au côté festif de notre soirée. Il serait difficile de décrire en détail cette deuxième partie de soirée, mais en deux mots : c’était très bon et très sympa ! Et pour ceux qui étaient là et qui ont demandé le nom du traiteur, voici ses coordonnées :
Cerisaie S.A.
Traiteur Evénementiel
info@cerisaie.be
T. +32 10 230 130
Rue Laid Burniat, 3
1348 Louvain-la-Neuve
Deuxième épisode de la mini série consacrée au tri dans FileMaker.
Introduction
Configurer les différents tris possibles dans un mode liste, en cliquant sur les libellés en tête des colonnes, peut s’avérer rapidement laborieux à faire, d’autant plus si votre solution comporte de nombreux modèles en mode liste avec le même système de tri.
En effet, FileMaker ne propose malheureusement aucun mécanisme natif permettant de choisir les rubriques de tri de manière dynamique, ce qui force à concevoir des scripts de tri remplis de très nombreuses conditions afin de lancer le bon tri suivant l’en-tête de colonne cliquée, et donc la valeur passée en paramètre au script de tri.
Par bonheur, quelques techniques existent pour contourner partiellement cette limitation et ainsi bénéficier d’un choix dynamique pour les rubriques de tri.
Dans cet article nous allons explorer l’une de ces techniques, elle ne concernera que les développeurs et utilisateurs de FileMaker (FM) sous environnement macOs, car elle est basée sur la technologie AppleScript (AS).
Exécuter du code AppleScript dans et depuis FileMaker Pro est possible depuis les toutes premières versions du logiciel, cela reste encore l’un de ses points forts sous macOS (même si, pour des raisons de compatibilité avec d’autres plate-formes, il est hélas souvent délaissé dans les projets professionnels).
Nous allons donc voir comment mettre rapidement en place un script de tri dynamique et générique, utilisable tel quel dans tous vos modèles liste, avec juste un zeste de code AppleScript.
Préparation
Pour commencer, de quoi allons nous avoir besoin ?
De très peu de choses : juste de deux rubriques globales de travail, qui peuvent être crées dans n’importe quelle table, mais qui trouveraient une place naturelle dans une table “Paramètres” (ou “Settings”).
Voici quelques explications à propos de ces deux rubriques (le suffixe “_g” est pour signaler leur portée globale) :
Tout d’abord, une rubrique de type texte, nommée par exemple “tri_rubrique_g”, qui contiendra le nom complet (table::rubrique) de la rubrique de tri ;
Ensuite, une rubrique de type nombre, nommée “tri_ordre_g” par exemple, qui contiendra une valeur booléenne indiquant l’ordre de tri : 0 = ordre descendant , 1 = ordre ascendant (pour s’assurer d’avoir toujours une valeur booléenne, on peut activer une entrée auto calculée avec le code suivant : ObtenirCommeBooleen ( Contenu ) ) ;
Le principe est simple : on passe le nom complet (table::rubrique) de la rubrique à trier en paramètre au script FileMaker de tri, si ce nom est identique à celui déjà mémorisé dans la rubrique globale “tri_rubrique_g”, alors on inverse tout simplement l’ordre de tri de la rubrique “tri_ordre_g”.
Si le nom passé en paramètre est différent de celui mémorisé, alors on mémorise ce nouveau nom dans la rubrique “tri_rubrique_g” et on règle la valeur de l’ordre de tri “tri_ordre_g” à 1 (tri ascendant par défaut).
Bon, pas trop compliqué jusqu’à là… voyons maintenant quel code AppleScript nous allons utiliser et comment l’exécuter…
AppleScript
FileMaker propose deux mécanismes pour exécuter un code AppleScript au sein d’un script avec l’action “Exécuter AppleScript” (présent dans la section “Divers” de la liste des actions) :
“AppleScript Calculé” : il s’agit d’y inscrire le code AppleScript comme si c’était du simple texte, FileMaker fera une interprétation puis une compilation à la volée du code avant son exécution, à chaque fois que le script FileMaker sera lancé. Dans ce mode, le passage de paramètres au code AppleScript est plutôt simple, il se fait par simple concaténation à l’intérieur du code ;
“AppleScript Natif” : il s’agit d’y inscrire le code AppleScript brut, qui sera compilé une seule fois à la validation du dialogue, puis il sera prêt à être exécuté tel-quel à chaque lancement du script FileMaker. Ici, le passage de paramètres au code AppleScript est un peu plus compliqué à mettre en place, il faudra par exemple prévoir des rubriques dédiées (nous ne verrons pas ce cas de figure ici).
Nous allons donc utiliser du code AppleScript calculé, plus simple à implémenter avec le passage des paramètres.
Plusieurs techniques sont possibles, comme :
Utiliser le code AppleScript directement dans le dialogue de l’action de script (solution la plus directe, souvent suffisante) ;
Placer le code AppleScript dans une rubrique globale et utiliser des balises pour être remplacées par les bons paramètres ;
Placer le code AppleScript dans une fonction personnalisée, puis utiliser les paramètres de la fonction FileMaker pour passer les paramètres à AppleScript.
Comme ici nous travaillons en local, la solution 2 avec la rubrique globale est celle que nous allons utiliser, plus simple d’accès pour notre démo. En revanche, pour une utilisation avec des fichiers hebergés dans un serveur, la solution 3 avec une fonction personnalisée semble la plus appropriée.
Dans tous les cas, le code AppleScript demeure le même, seule la technique du passage des paramètres diffère.
Voyons donc notre code AppleScript avec quelques commentaires (précédés de deux tirets “–“) pour bien comprendre le rôle de chaque instruction :
-- Structure 'try' de contrôle au cas où une erreur se produisait pendant l'exécution
try
-- On récupère les valeurs de la rubrique et de l'ordre de tri dans des variables AS
-- Pour ce faire, on utilise deux balises, délimitées par deux caractères dièse "##",
-- qui seront remplacées par les valeurs issues des rubriques globales de travail
-- Le nom complet (table::rubrique) de la rubrique de tri
set sRubrique to "##tri_rubrique##"
-- Le numéro booléen correspondant à l'ordre de tri
set nOrdre to ##tri_ordre##
-- On active FileMaker pour lancer le tri
tell current application
-- On récupère la bonne propriété d'ordre de tri à utiliser
set pOrdre to contents of item (nOrdre + 1) of {descending, ascending}
-- On lance le tri dans le modèle actif sur la bonne rubrique et le bon ordre
sort current layout by field sRubrique in order pOrdre
end tell
on error err_mssg number err_num
-- On affiche un dialogue d'infos si une erreur se produit lors de l'exécution
display dialog ("" & err_num & " : " & err_mssg)
end try
Les deux balises “##tri_rubrique##” et “##tri_ordre##” seront remplacées avec la fonction “Substituer()”, au sein du script FileMaker, par les valeurs issues des rubriques globales de travail “tri_rubrique_g” et “tri_ordre_g” respectivement.
Voyons maintenant de quoi il sera fait le code de notre script FileMaker…
Script FileMaker
Nous allons commencer par initialiser une variable “$rubrique” avec la valeur passée en paramètre au script. En effet, chaque bouton qui fera appel à ce script de tri, passera en paramètre le nom complet (table::rubrique) de la rubrique de tri.
Si le paramètre est vide, alors on annule le tri.
Comme expliqué plus haut, on défini l’ordre de tri selon que la valeur de la variable “$rubrique” et le contenu de la rubrique globale “tri_rubrique_g”, si elles sont identiques, alors on se contente d’inverser l’ordre de tri, sinon, on règle l’ordre de tri à la valeur par défaut = 1 (tri ascendant).
Ensuite on rensigne la rubrique globale “tri_rubrique_g” avec la variable “$rubrique”, on peut désormais faire le remplacement des balises “##” dans le code AppleScript avant de lancer son exécution.
Voici le code du script FileMaker complet avec les commentaires :
# Commandes de contrôle… comme d'hab…
Gestion erreurs [ Oui ]
Autor. annulation utilisateur [ Non ]
#
# On récupère le paramètre de script et on efface tout éventuel espace de bord inutile
Définir variable [ $rubrique ; Valeur: SupprimerEspace ( Obtenir ( ParamètreScript ) ) ]
#
# Si une touche morte est enfoncée ou si la rubrique de tri est vide, alors on initialise les rubriques globales, on annule le tri et on active le premier enregistrement
Si [ ( Obtenir ( TouchesSpécialesActives ) ) Or ( EstVide ( $rubrique ) ) ]
Définir rubrique [ Settings::tri_rubrique_g ; "" ]
Définir rubrique [ Settings::tri_ordre_g ; 1 ]
Annuler tri des enreg.
Afficher enreg/requête/page [ Premièr(e) ]
Fin de script [ Résultat de texte: "Annulation du tri…" ]
Fin de si
#
# On défini et mémorise l'ordre de tri dans sa rubrique globale selon la rubrique de tri choisie : si même rubrique, alors on inverse l'ordre de tri, sinon on utilise la valeur par défaut 1 (ordre ascendant)
Définir rubrique [ Settings::tri_ordre_g ; ObtenirCommeBooleen ( Si ( EstEgal ( $rubrique ; Settings::tri_rubrique_g ) ; Not Settings::tri_ordre_g ; 1 ) ) ]
#
# On mémorise la nouvelle rubrique de tri choisie dans sa rubrique globale
Définir rubrique [ Settings::tri_rubrique_g ; $rubrique ]
#
# On valide tout ça…
Valider enreg./requêtes [ Avec boîte de dialogue: Non ]
#
# On initialise une variable avec le code AppleScript à exécuter, en remplaçant au passage les balises par les vraies valeurs de travail
Définir variable [ $applescript ; Valeur: Substituer ( Settings::tri_applescript_g ; [ "##tri_rubrique##" ; Settings::tri_rubrique_g ] ; [ "##tri_ordre##" ; Settings::tri_ordre_g ] ) ]
#
# On exécute le tri avec un AppleScript calculé
Exécuter AppleScript [ $applescript ]
#
# À la fin du tri, on active le premier enregistrement
Afficher enreg/requête/page [ Premièr(e) ]
#
Fin de script [ Résultat de texte: "Tri effectué…" ]
#
# Code récupéré grâce au plugin MBS
Petite subtitilité ergonomique, nous avons ajouté un test sur les éventuelles touches spéciales actives lors du clic sur les boutons de tri, cela permet d’annuler le tri par simple clic d’un en-tête de colonne avec une touche morte enfoncée (commande, contrôle, option ou shift), cela évite de passer par un bouton dédié (même si cela reste toujours intéressant à proposer, surtout nécessaire si votre solution est utilisée avec FileMaker Go).
Voyons maintenant comment implémenter tout ceci dans notre modèle…
Implémantation
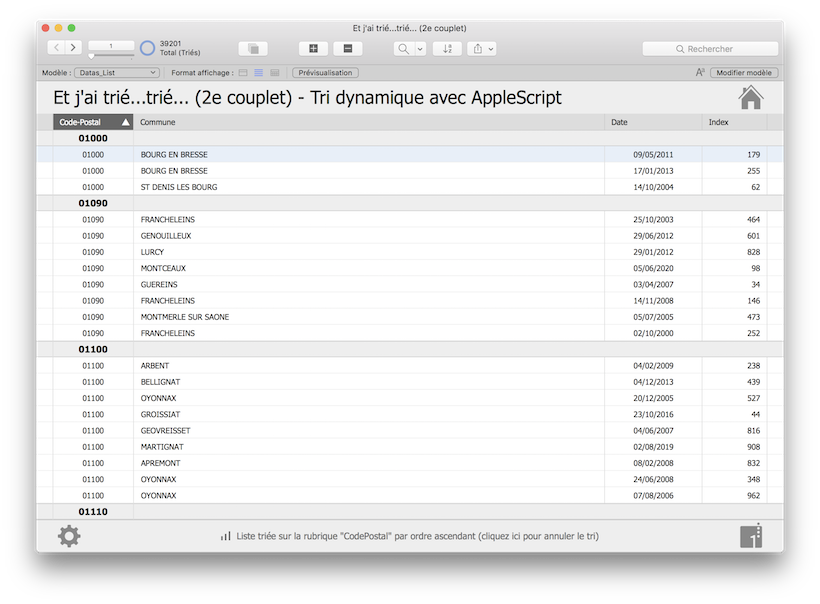
Nous allons donc construire un modèle liste, dans notre fichier de démo (communes de France), nous avons placé 4 rubriques, à savoir :
Code postal de la commune ;
Nom de la commune ;
Une date calculée aléatoirement entre les années 2000 et 2020 ;
Un numéro d’index aléatoire de 1 à 999.
Nous disposons donc, pour nos tests de tri, de deux rubriques de type texte (1 et 2) et de deux rubriques de type nombre (3 et 4).
Chaque en-tête de colonne sera donc un bouton qui lancera notre script FileMaker de tri, en passant comme paramètre le nom complet (table::rubrique) de la rubrique à trier (nous utilisons ici la fonction native ObtenirNomRubrique ( table::rubrique ) pour s’assurer d’avoir toujours le nom correct, quelque soient les modifications ultérieures).
Nous pouvons ajouter une mise en forme conditionnelle qui, en comparant le nom de la rubrique à trier avec celui existant dans la rubrique globale “tri_rubrique_g”, pourra changer l’aspect du bouton pour bien visualiser sur quelle colonne le tri a bien été effectué.
Nous pouvons également ajouter un indicateur de l’ordre de tri, dans notre fichier de démo nous utilisons la valeur de la rubrique globale “tri_ordre_g” comme affichage booléen avec deux caractères unicode représentant des flêches, une vers le haut “▲” (tri ascendant), l’autre vers le bas “▼” (tri descendant). L’affichage de cet indicateur sera géré par un masquage conditionnel sur le même principe, mais inversé, que celui de la mise en forme conditionnelle.
AppleScript offre beaucoup de possibilités avec FileMaker, comme celle présentée ici, même si d’autres solutions de tri dynamiques existent pour ce type d’utilisations en mode liste, certains natives FileMaker.
En tout cas, n’hésitez-pas à décortiquer le fichier de démo en pièce jointe ci-dessous, pour bien visualiser et comprendre toutes les techniques décrites ici, vous pourrez ensuite nous faire part de toutes vos questions et remarques dans les commentaires ci-dessous.
Premier épisode de la mini série consacrée au tri dans FileMaker.
Trier peut signifier regrouper les choses d’une même nature.
Dans cette démonstration, nous verrons comment procéder à des regroupements de données au moyen de tris, dans nos interfaces ou lors d’exportations d’enregistrements.
En exploitant les possibilités de regroupement par sous-récapitulatifs, l’utilisateur manipule les données afin de faire émerger des éléments d’analyse. En combinant les récapitulatifs aux tris sur base de statistiques, nos interfaces de rapports deviennent de véritables outils d’analyse.
Au moyen des données du fichier d’exemple ci-joint (résultats d’athlétisme pour les trois derniers Jeux Olympiques), nous montrons que les rapports peuvent offrir une vue analytique modulable très pertinente.
Pour analyser, il suffit de regrouper…et pour regrouper, il suffit de trier. C’est aussi simple.
PS: dans la vidéo, j’ai utilisé une terminologie assez spécifique à notre nomenclature 1-more-thing : je parle du “zkp”, comprenez “identifiant unique” – “clé primaire de la table”.
[vc_row bg_color=””][vc_column][vc_column_text]Voici peut-être un sujet un peu pointu, mais il ne fait jamais de mal d’interroger parfois les fondamentaux… essayons ici de faire le tour complet de la problématique de la casse en FileMaker.
D’abord, pour ne pas se perdre tout de suite, qu’est-ce que la “casse” ?
Ici, je parierais que beaucoup de ceux qui savent déjà ce qu’est la sensibilité à la casse ne savent pas d’où vient le mot.
Ce terme nous vient de l’imprimerie, et plus précisément de la typographie : pour composer une page, il fallait attraper très rapidement des caractères en plomb. On les rangeait alors dans une sorte de caissette en bois compartimentée et que l’on appelait casse. Chaque compartiment contenait les plombs pour un caractère de la fonte (ou police). Or on ne les rangeait pas par ordre alphabétique mais par fréquence d’utilisation. Les minuscules étant bien plus employées que les majuscules, leurs compartiments devaient être proches du typographe, et donc en “bas-de-casse”, les majuscules en “haut-de-casse”.
Pour ceux que cela amuse, je vous invite à réfléchir aux termes encore employés à l’ère de l’informatique : casse, fonte, valise de police…
FileMaker comporte des fonctions de calcul qui nous permettent de manipuler la casse d’un texte :
Mais… qu’est-ce donc que la sensibilité à la casse ? C’est très simple : selon les environnements et le contexte, on considérera qu’une majuscule a la même valeur qu’une minuscule (insensibilité à la casse) ou au contraire qu’elle a une valeur différente (sensibilité à la casse)
Par exemple dans un dictionnaire français comprenant des noms propres, comme par exemple le Larousse, on ne fera pas de différence de classement entre une majuscule et une minuscule, ainsi un nom propre avec une majuscule se retrouvera parmi des noms communs, adjectifs ou autre adverbes en minuscules.
Dans d’autres contextes, on fera nettement la différence.
Bien souvent dans les langages informatiques, la plupart des traitements sont effectués avec sensibilité à la casse. Cela vient notamment du fait que les premiers ordinateurs travaillaient sur des jeux réduits de caractères (ASCII), et ne pouvaient se permettre de s’encombrer de considérations telles que a = A à chaque fois qu’ils devaient analyser un a.
Mais FileMaker, qui comme vous le savez a été pensé pour des humains normaux (ou presque), fait l’effort depuis très longtemps de l’insensibilité à la casse. Ainsi, vous pouvez comparer des chaînes de caractères telles que “Milan” (la ville) et “milan” (le rapace), et constater une égalité :
"Milan" = "milan"
Ceci fonctionne aussi bien dans les calculs que dans les index (utilisés dans les liens, listes de valeurs ou recherches).
D’ailleurs, on peut noter qu’il en est de même avec les caractères accentués : “à” = “a”, si toutefois la langue d’indexation est le français (en russe par exemple, le E (yé) et le Ë (yo) sont bien deux lettre différentes, avec chacune sa place dans l’alphabet et dans le dictionnaire. Mais il s’agit de caractères différents de l’alphabet latin, bien que visuellement similaires)
On pourrait donc penser que “FileMaker n’est pas sensible à la casse”, un point c’est tout.
Or ce serait bien ennuyeux si on en restait là.
Il existe un nombre limité de cas où FileMaker est sensible à la casse (case sensitive en anglais), essayons d’en faire le tour.
Tout d’abord, certaines fonctions de calcul le sont. On en cite souvent trois en oubliant que FileMaker continue d’évoluer et que ça n’est pas parce qu’en 1914 il y en avait trois qu’il y en a forcément trois aujourd’hui.
EstEgal ( TexteOrigine ; TexteComparaison ) – EstEgal ( “monMotDePasseSuperSecret” ; “monmotdepassesupersecret” ) retournera 0 car les deux chaînes ne sont pas identiques, alors que, rappelons-le, “monMotDePasseSuperSecret” = “monmotdepassesupersecret” retournera 1 (l’opérateur de comparaison = n’est pas sensible à la casse). Soit dit en passant, si votre mot de passe est super secret, préférez une comparaison de hash MD5 plutôt que de stocker le mot de passe en clair dans la base de données !
Et donc on aurait ainsi fait le tour de la question ? Que nenni…
Depuis FileMaker 12, la fonction ExecuterSQL ( RequêteSQL ; séparateurRubrique ; séparateurLigne{; arguments…} ) – entrouvre la porte au langage de requête SQL au sein de FileMaker (d’un point de vue strict, cette porte était déjà entrouverte pour les connexions ODBC ou les plugins). Or SQL est en grande partie sensible à la casse, même si là encore, l’implémentation de FileMaker est assez tolérante.
Soit une table “maTable” contenant les colonnes “champ1” avec les valeurs A1, A2, A3, et “Champ2″ et les valeurs B1, B2, B3 :[/vc_column_text][ish_table align=”center” header_bg_color=”color7″ header_text_color=”color4″ border_color=”color7″]
ID
champ1
Champ2
1
A1
B1
2
A2
B2
3
A3
B3
[/ish_table][vc_column_text]La formule suivante :
ExecuteSQL ( "SELECT champ1 from matable where champ2 = 'B3'" ; "" ; "" )
retournera bien “A3”. Autrement dit, le nom des tables et des colonnes n’est pas sensible à la casse, mais c’est maintenant le cas de la plupart des implémentations SQL. Les mots clef comme SELECT, FROM ou WHERE dans cette requête sont toujours insensibles à la casse. Par convention, on les écrit en majuscules, sauf ici où j’ai voulu illustrer l’insensibilité à la casse.
en revanche, la même formule dans laquelle on changera le critère ainsi :
ExecuteSQL ( "SELECT champ1 from matable where champ2 = 'b3'" ; "" ; "" )
retournera du vide, car “b3” n’est pas égal à “B3” dans une requête SQL.
Astuce : si ce comportement vous dérange, vous pouvez utiliser la fonction SQL lower :
ExecuteSQL ( "SELECT champ1 from matable where lower ( champ2 ) = 'b3'" ; "" ; "" )
Donc il y a bien quatre et non trois fonctions sensibles à la casse…
… est-ce tout ?
Non ! depuis FileMaker 16, de nouvelles fonctions sont apparues :
Au passage, on remarquera que FileMaker a apparemment décidé de ne plus traduire le nom des fonctions de calcul. Le traducteur a dû être sensible à la casse… sociale.
Donc essayons cette formule :
Uniquevalues ( list ( "a" ; "b" ; "B" ; "A" ; "à" ; "À" ) ; 1 ; "" )
le résultat est :
a
b
donc aucune sensibilité à la casse.
en modifiant légèrement, pour explorer :
Uniquevalues ( list ( "A" ; "a" ; "b" ; "B" ; "A" ; "à" ; "À" ) ; 1 ; "" )
le résultat est
A
b
donc on voit que le A majuscule est retourné à la place du a minuscule parce qu’il est trouvé en premier, mais comme on n’est pas ici sensible à la casse, le a minuscule n’est pas retourné en plus.
Mais… n’avais-je pas sous-entendu que ces fonctions étaient justement sensibles à la casse ?
Et bien… c’est qu’elles peuvent l’être !
Le dernier paramètre (facultatif) de ces fonction est locale, et il permet justement de préciser dans quelle “langue” on veut trier ou dédoublonner.
Or s’il est une langue que nous parlons vous et moi couramment, c’est bien… l’Unicode.
Dans l’aide, vous constatez que deux variantes peuvent être utilisées : Unicode_Raw et Unicode_Standard.
Uniquevalues ( list ( "a" ; "b" ; "B" ; "A" ; "à" ; "À" ) ; 1 ; "Unicode_Raw" )
retourne
a
b
B
A
à
À
autrement dit chaque caractère est différent (accentué, non accentué, majuscule, minuscule…). Voici donc deux nouvelles fonctions (SortValues et UniqueValues) sensibles à la casse !
Uniquevalues ( list ( "a" ; "b" ; "B" ; "A" ; "à" ; "À" ) ; 1 ; "Unicode_Standard" )
retourne
a
b
à
on voit qu’on perd la sensibilité à la casse mais pas celle aux accents.
Je crois que nous avons fait le tour de la question de la sensibilité à la casse dans FileMaker. J’espère que vous aurez appris quelque chose. N’hésitez pas à prolonger la discussion dans les commentaires ci-dessous.[/vc_column_text][/vc_column][/vc_row]
[vc_row bg_color=””][vc_column][vc_column_text]Vous n’en entendez peut-être même pas parler, mais plusieurs pays d’Afrique, notamment la Somalie, le Sud Soudan et le Nigeria connaissent actuellement une famine grave et qui est en train de tourner à la catastrophe majeure.
La sous-médiatisation de cette famine entraîne un sous-financement des ONG capables d’agir. Or pour une famine, il faut agir très rapidement.
On ne peut pas tout faire, mais ce qu’on peut faire, on doit le faire. Nous avons donc décidé de participer au financement de ces ONG, via Famine 12-12 en renversant la totalité de la marge que nous dégageons sur la vente de licences FileMaker.
Dès à présent, toute licence FileMaker que vous commandez auprès de nous générera un don.
Si le renouvellement de vos licences n’intervient pas rapidement, nous vous proposons de renouveler anticipativement et prenons bien sûr à notre charge la gestion de tout cela.
N’hésitez pas à nous contacter pour en savoir plus.
Et, si vous n’avez pas besoin de licences FileMaker mais que vous souhaitez soutenir cette action, n’hésitez pas et rendez-vous sur la page du projet ;-)[/vc_column_text][ish_counter el_text=”1641″ text_color=”color7″ tag_size=”h3″ icon=”ish-icon-heart” additional_text=” € collectés depuis le lancement de l’opération” icon_color=”color7″][/vc_column][/vc_row]
Tableau est un puissant outil d’analyse des données et depuis peu, il est devenu possible d’y connecter nos bases de données FileMaker à l’aide d’un connecteur dédié livré avec la version 16 de FileMaker Server.
Alors que nous testions ses possibilités dans le but d’en faire profiter nos clients, nous avons eu une mauvaise surprise : les statistiques que nous obtenions étaient fausses…
Après une recherche en profondeur, nous avons fini par en découvrir la cause : le séparateur de décimal.
Contre toute attente, et ce, malgré la norme du standard JSON, FileMaker Server renvoie des nombres formatés selon les paramètres du système. Or dans nos contrées, c’est la virgule alors que le standard JSON attend un point.
Résultat : tous les nombres décimaux sont ignorés par Tableau et les statistiques que vous obtenez sont faussées
Que faire ? Changer le format du système pour le forcer à renvoyer des nombres justes ? Cette option ne nous enchante guère, elle pourrait de plus avoir des conséquences inattendues.
Heureusement, nous sommes parvenu à trouver un moyen de contournement bien plus simple et efficace !
Tout se passe au niveau du connecteur FileMaker pour Tableau, dans un petit fichier javascript répondant ou doux nom de “fm_connector_util.js” que vous trouverez dans le dossier “/Library/FileMaker Server/Web Publishing/publishing-engine/node-wip/public/tableau/js”.
Dans ce fichier se cache une fonction qui permet de convertir à la volée les dates “FileMaker” dans un format de date compatible avec Tableau et il s’est avéré très facile d’étendre son champ d’action aux nombres !
En attendant un correctif officiel de la part de FileMaker nous avons décidé de partager ce fix avec la communauté par ce qu’il n’y a pas de raison pour que nous soyons les seuls à pouvoir utiliser Tableau en Europe !
Placez le simplement dans le dossier “FileMaker Server/Web Publishing/publishing-engine/node-wip/public/tableau/js” (remplacez le fichier existant), rechargez votre source de donnée dans Tableau et le tour est joué !
NB : Pensez à faire une copie de sauvegarde du fichier original avant d’appliquer le correctif !
L’API PHP de FileMaker est elle en fin de vie ? C’est une question que l’on pourrait se poser depuis qu’une nouvelle technologie est apparue dans FileMaker Server 16 pour nous permettre de partager les données d’une base FileMaker au travers d’un site web: l’API REST. Cependant, bien que cette nouvelle API (encore en version beta – [EDIT : en version finale avec FileMaker 17]) apporte un vrai vent de fraîcheur et offre de belles perspectives d’évolution, elle n’en demeure pas moins limitée pour l’instant et moins adaptée à une architecture web classique où le serveur web occupe un rôle central.
Aussi, la publication XML couplée à l’API PHP de FileMaker reste encore à ce jour le meilleur moyen pour partager et utiliser une solution directement sur le Web.
Elle souffre malgré tout de certaines lacunes : développée pour être compatible avec PHP 4 à sa sortie (une version encore répandue à l’époque), l’API PHP originale (téléchargement) n’a quasiment pas évolué depuis (à part quelques corrections mineures).
Tous ceux qui l’ont utilisée, se rappellent certainement des nombreuses alertes indiquant l’utilisation des méthodes dépréciées dès lors qu’elles étaient exécutées avec une version plus récente de PHP. Bien que ces erreurs aient été corrigées depuis, l’avènement de PHP 7 les a malheureusement remises au goût du jour.
Ce manque d’évolution a rendu son code vétuste, il n’est plus du tout en phase avec les nouvelles méthodes de développement qui ont émergé ces dernières années dans l’univers de PHP, et de fait ce retard d’actualisation rend son intégration compliquée dans tout projet utilisant un framework ou un CMS “moderne”.
Une mise à jour de cette bibliothèque était devenue de plus en plus nécessaire pour assurer sa pérennité. Seulement voilà, bien que PHP ait encore de beaux jours devant lui au vu de ses améliorations régulières et de sa grande popularité, FileMaker a décidé de faire les yeux doux aux technologies plus en vogue actuellement, telles que les frameworks JavaScript. Inutile dès lors d’espérer une quelconque évolution de ce côté-là (la publication XML n’est et ne sera a priori jamais disponible sur FileMaker Cloud par exemple).
Il ne restait donc qu’une seule solution : retrousser ses manches et mettre les mains dans le cambouis afin de prodiguer une petite cure de jouvence à notre chère API PHP !
Méthodologie
Évidemment, avant de toucher à la moindre ligne de code, il fallait se plonger d’abord, tel un moine cistercien, dans une longue et approfondie étude du code source original, pour comprendre sa structure, son fonctionnement et ses particularités afin de bien saisir l’ampleur du chantier à venir.
Très vite, deux exigences se sont imposées : simplifier au mieux le code source (tout en essayant de l’optimiser), et le moderniser afin de le rendre conforme aux standards de développement actuels, notamment ceux recommandés par le groupe PHP-FIG, dans l’objectif d’assurer une meilleure interopérabilité avec la plupart des frameworks et CMS PHP modernes.
Côté simplification, les changements se sont portés principalement sur une nouvelle stratégie de gestion des erreurs et sur la réécriture d’une partie du code afin de respecter la norme PSR-2 (conventions d’écriture du code source).
La nouvelle gestion d’erreurs consiste à s’affranchir des tests conditionnels ponctuels au bénéfice d’une seule structure générale de test par exceptions, avec un bloc de type “try / catch” englobant les principales instructions de travail (voir un exemple de code plus bas). La méthode originale reste cependant toujours fonctionnelle afin d’assurer une compatibilité descendante.
Cette première étape terminée, il fallait maintenant consolider la compatibilité avec les versions les plus récentes de PHP et en tirer le meilleur parti pour moderniser au maximum le code.
Dès lors, concernant la modernisation du code source, l’ajout des espaces de noms, sur l’ensemble des classes de l’API, couplé à un système “d’auto-chargement”, comme le préconise la spécification PSR-4, se sont imposés, assurant de facto la compatibilité avec les frameworks PHP les plus en vogue du moment.
Cette technique a entraîné un changement en profondeur de la structure des fichiers, sans pour autant modifier le fonctionnement d’origine de l’API, et ce, dans le but de garantir une parfaite compatibilité avec les projets basés sur l’API-PHP de FileMaker originale.
structure des fichiers de l’API PHP de FileMaker originale
structure des fichiers de l’API PHP de FileMaker réécrite
S’ouvrir au reste du monde
Nous y étions ! l’API PHP de FileMaker était enfin modernisé ! Ne restait plus alors qu’à l’ouvrir au reste du monde libre !
En effet, depuis quelques années maintenant, les projets PHP se sont structurés autour d’une multitude de bibliothèques tierces, à l’instar de beaucoup d’autres langages tel que java, javascript, …
Afin de simplifier la gestion de ces multiples codes source et d’assurer leur mise à jour sans effort (le code étant maintenu par d’autres développeur), un outil désormais très populaire a été créé : Composer. Celui-ci permet de gérer, à l’aide d’un simple fichier de configuration (json) l’ensemble des bibliothèques tierces d’un projet, en assurant l’installation et la mise à jour.
De toute évidence, notre API se devait de rejoindre la communauté pour achever sa mutation, ce qui nécessita quelques adaptations non sans conséquences : cela a conduit à abandonner le fichier de configuration original de l’API (dans le monde de Composer, une bibliothèque tierce ne doit jamais être modifiée pour garder le bénéfice des mises à jour). Cela implique qu’il est désormais livré avec une configuration « par défaut », qu’il vous appartient de modifier au moment de son instanciation.
Evolutions
Notre nouvelle API fin prête, il nous tardait de l’intégrer dans un projet d’ampleur pour en mesurer son potentiel, ce qui fut rapidement le cas ! Un projet nécessitant l’emploi d’un Framework (yii2) s’étant rapidement présenté.
Ce premier galop d’essai a permis de mettre en lumière certaines lacunes qui n’étaient pas forcément apparues lors de la réécriture, notamment le besoin de faciliter le débogage lors des développements et d’améliorer la communication avec des bibliothèques tierces.
Ainsi, un certain nombre de nouvelles fonctionnalités ont été implémentées au fil de l’eau, dont voici une liste non exhaustive (certaines développées spécifiquement, d’autres issues des fonctions déjà existantes dans l’API-XML de FileMaker, mais non implémentées dans l’API-PHP de FileMaker d’origine) :
Choix du format de date en entrée et sortie de l’API ;
Prise en charge de la « pagination » lors de l’exécution d’un script ;
Définition de globales à l’exécution d’une recherche ;
Méthode permettant de récupérer la dernière requête (URL) envoyée au serveur FileMaker (extrêmement utile pour le debogage en phase de développement);
L’objet “Layout” peut désormais renvoyer le nom de la table source (en plus du nom de l’occurrence de table) via la propriété $layout->table, permettant une gestion plus simple des contextes d’exécution ;
Méthode permettant la récupération d’une liste de valeurs associée à un champ sur un modèle (les listes peuvent ainsi être renommées sans impact sur votre site web).
Installation et configuration
Voici, en quelques lignes, les principales étapes pour installer et mettre en service cette nouvelle API-PHP de FileMaker.
Il y a deux méthodes d’installation de cette API :
Via la solution “Composer”, en ajoutant "airmoi/filemaker" : "*" à votre fichier de configuration ;
Manuellement en téléchargeant les dernières sources sur le site de GitHub dédié et en installant les fichiers décompressés dans votre projet : Dépot GitHub
Pour le chargement et l’activation de l’API, c’est très simple, il suffit d’inclure le fichier “autoload.php” qui se trouve à la racine du projet (facultatif en cas d’installation via Composer): require ('/path/to/API/autoload.php');
Vous devez ensuite déclarer la classe à utiliser à l’aide de son espace de nom (l’autoloader se chargeant de trouver automatiquement les fichiers à charger pour assurer le bon fonctionnement de l’API) : use airmoi\FileMaker\FileMaker;
Le fichier de configuration ayant disparu, deux méthodes sont disponibles pour configurer votre projet :
Utilisation de la méthode PHP de FileMaker : setProperty('name', $value), qui peut servir pour configurer individuellement les différents paramètres du projet ;
Utilisation d’un tableau de paramètres directement à la création de l’objet FileMaker, par exemple : new FileMaker($db, $host, $user, $pass, ['dateFormat' => 'd/m/Y'])
permettant de configurer le projet en une seule instruction.
Voici un code d’exemple illustrant tout ceci :
[code language=”php”]
// Chargement de l’API
require_once (‘/path/to/API/autoload.php’);
// Définition de l’espace de noms
use airmoi\FileMaker\FileMaker;
// Création de l’objet FileMaker avec le tableau de paramètres
$fm = new FileMaker($db, $host, $user, $pass, $options);
// Récupération de la liste de tous les modèles et leur affichage
$layouts = $fm->listLayouts();
foreach ($layouts as $layout) {
echo $layout . ‘
‘;
}
[/code]
Exemples d’utilisation
Gestion des erreurs : l’ancienne méthode
[code language=”php”]
// Réglage des options de configuration
$options = [
‘errorHandling’ => ‘default’,
];
$fm = new FileMaker($db, $host, $user, $pass, $options);
// Récupération d’un modèle et test sur une éventuelle erreur
$layout = $fm->getLayout(‘sample’);
if (FileMaker::isError($layout)) {
echo "Error: " . $layout->getMessage();
exit;
}
// Execution de la requete
$result= $fm->newFindAnyCommand(‘sample’)->execute();
if (FileMaker::isError($record)) {
echo "Error: " . $record->getMessage();
exit;
}
// Récupération d’un enregistrement
$record = $result->getFirstRecord();
if (FileMaker::isError($record)) {
echo "Error: " . $record->getMessage();
exit;
}
// Modification de l’enregistrement
$record->setField(‘text_field’, str_repeat(‘a’, 51));
$record->commit();
if (FileMaker::isError($record)) {
echo "Error: " . $record->getMessage();
exit;
}
[/code]
L’ancien système de gestion d’erreur s’obtient en réglant le paramètre “errorHandling” à la valeur “default”.
Comme on peut le constater, elle vous oblige à répéter vos contrôles pour pratiquement chaque instruction.
Gestion des erreurs : la technique des exceptions
[code language=”php”]
//Le mode de gestion par Exception est configuré par défaut
//il n’est donc pas nécessaire de le préciser dans les options
$fm = new FileMaker($db, $host, $user, $pass);
try {
// Récupération d’un modèle
$layout = $fm->getLayout(‘sample’);
// Récupération d’un enregistrement en 1 ligne
$record = $fm->newFindAnyCommand(‘sample’)->execute()->getFirstRecord();
// Modification de l’enregistrement
$record->setField(‘text_field’, str_repeat(‘a’, 51));
$record->commit();
} catch (FileMakerException $e) {
//Gestion des erreurs ayant pu survenir à n’importe quelle ligne
printf (‘Erreur %d : %s ‘, $e->getCode(), $e->getMessage());
}
[/code]
Comme vous pouvez le constater, la gestion d’erreur par exception via le bloc try/catch permet de réduire de façon considérable le nombre de lignes de code.
Toute sa logique peut être centralisée, ce qui simplifie la lecture du code, améliore sa fiabilité et sa maintenance.
Désormais, avec cette nouvelle API, on peut demander quel intervalle de données récupérer. Par exemple, on peut demander d’avoir les données correspondant aux enregistrements de 5 à 25. Cela permet d’obtenir une pagination sur un résultat de script, ce qui était impossible auparavant
Fonctionnalité très pratique, car elle permet désormais de définir une globale au moment de l’exécution d’une requête, ce qui vous permettra par exemple de récupérer, dans vos résultats, des données liées au travers d’une globale.
Conclusion
Comme expliqué au début de l’article, l’API PHP de FileMaker avait bien besoin d’un sacré coup de jeune pour s’adapter à l’évolution des technologies les plus récentes, notamment concernant l’interaction avec les frameworks PHP modernes.
Cette réécriture a nécessité de nombreuses heures de travail et d’innombrables tests. Le résultat est plus qu’encourageant puisque cette nouvelle version est désormais utilisée quotidiennement en production sur plusieurs projets professionnels gérés par l’équipe de 1-more-thing.
Mais, bien qu’elle soit en l’état assez stable et aboutie pour être utilisée en production, cette réécriture n’est cependant pas encore terminée, bien d’autres améliorations sont en cours et d’autres à prévoir. Si vous souhaitez contribuer à son évolution, vous êtes évidemment les bienvenus : Dépot GitHub.
Un grand merci à tous ceux qui ont participé, directement ou indirectement, à la réalisation de ce projet, et un remerciement tout particulier à Matthias Kühne pour toutes ses contributions.
Is the FileMaker PHP API at end of life? This is a question that could arise since a new technology appeared in FileMaker Server 16 to allow us to share data from a FileMaker database through a website: the REST API. However, although this new API (still in beta version – [EDIT: in final version with FileMaker 17]) brings a real wind of freshness and offers beautiful prospects of evolution, it remains nonetheless limited for the instant and less adapted to a classic web architecture where the web server occupies a central role.
Therefore XML publishing combined with the FileMaker PHP API is still often the best way to share and use a solution directly on the Web.
It still suffers from some shortcomings: developed to be compatible with PHP 4 at its release (a version still widespread at the time), the original PHP API (download) has hardly changed since (except for some minor corrections) ).
Anyone who has used it, certainly remember many alerts indicating the use of deprecated methods as soon as they were run with a newer version of PHP. Although these errors have since been corrected, the advent of PHP 7 has unfortunately brought them up to date.
This lack of evolution has made its code obsolete, it is not at all in step with the new development methods that have emerged in recent years in the PHP universe, and in fact this update delay makes its integration complicated in any project using a framework or a “modern” CMS.
An update of this library had become more and more necessary to ensure its durability. But here, although PHP still has a bright future ahead of time given its steady improvements and popularity, FileMaker has decided to take a good look at the more popular technologies such as JavaScript frameworks. No need therefore to hope for any evolution on this side (the XML publication is and will never be available on FileMaker Cloud for example).
So there was only one solution: roll up his sleeves and put his hands in the grease to give a little makeover to our dear PHP API!
Methodology
Obviously, before touching any line of code, one had to dive first, like a Cistercian monk, into a long and thorough study of the original source code, to understand its structure, its functioning and its particularities in order to grasp well the magnitude of the upcoming work.
Very quickly, two requirements were imposed: simplifying the source code as much as possible (while trying to optimize it), and modernizing it to bring it into line with current development standards, especially those recommended by the PHP-FIG group, in the goal of ensuring better interoperability with most modern PHP frameworks and CMSs.
On the simplification side, the changes mainly focused on a new error management strategy and rewriting part of the code in order to comply with the PSR-2 standard (source code writing conventions).
The new error handling is to overcome the occasional conditional tests for the benefit of a single general test structure by exception, with a block of type “try / catch” encompassing the main work instructions (see a sample code lower). The original method still remains functional, however, to ensure backward compatibility.
This first step was completed, it was now necessary to consolidate compatibility with the most recent versions of PHP and make the most of it to modernize the code as much as possible.
Therefore, concerning the modernization of the source code, the addition of namespaces, on all the classes of the API, coupled with a “self-loading” system, as recommended by the PSR-4 specification, have imposed themselves, ensuring de facto compatibility with the most popular PHP frameworks of the moment.
This technique has resulted in a profound change in the file structure, without changing the original operation of the API, in order to ensure full compatibility with projects based on the API-PHP of Original FileMaker.
Original FileMaker PHP API file structure
New PHP API file structure
Open to the World
We were there ! the PHP API of FileMaker was finally modernized! Then remained open to the rest of the free world!
Indeed, for some years now, PHP projects have been structured around a multitude of third-party libraries, like many other languages such as java, javascript, …
In order to simplify the management of these multiple source codes and to ensure their updating without effort (the code being maintained by other developers), a very popular tool has now been created: Composer. It allows to manage, with the help of a simple configuration file (json) all the third libraries of a project, ensuring the installation and the update.
Obviously, our API had to join the community to complete its mutation, which necessitated some adaptations not without consequences: that led to abandon the original configuration file of the API (in the world of Composer, a third library should never be modified to keep the benefit of updates). This implies that it is now delivered with a “default” configuration, which you must modify at the moment of instantiation.
Evolutions
Our new API ready, we were eager to integrate it into a large project to measure its potential, which was quickly the case! A project requiring the use of a Framework (yii2) was quickly presented.
This first test run highlighted some deficiencies that did not necessarily appear during the rewrite, including the need to facilitate debugging during development and improve communication with third-party libraries.
Thus, a certain number of new features have been implemented over the water, of which here is a non-exhaustive list (some developed specifically, others resulting from functions already existing in FileMaker API-XML, but not implemented in the original FileMaker PHP-API):
Choice of date format input and output of the API;
Support for “paging” when running a script;
Definition of global at the execution of a search;
Method to retrieve the last request (URL) sent to the FileMaker server (extremely useful for debugging in the development phase);
The “Layout” object can now return the name of the source table (in addition to the name of the table instance) via the $ $layout->table property, allowing easier management of execution contexts;
Method for retrieving a list of values associated with a field on a model (lists can be renamed without impact on your website).
Installation and configuration
Here are some of the main steps to install and implement this new FileMaker PHP API.
There are two methods of installing this API:
Via the “Composer” solution, adding "airmoi/filemaker" : "*" to your configuration file;
Manually by downloading the latest sources from the dedicated GitHub website and installing the uncompressed files in your project: GitHub Repository
For the loading and the activation of the API, it is very simple, it is enough to include the file “autoload.php” which is at the root of the project (optional in case of installation via Composer): require ('/path/to/API/autoload.php');
You must then declare the class to use using its namespace (the autoloader is responsible for automatically finding the files to load for the proper functioning of the API): use airmoi\FileMaker\FileMaker;
Since the configuration file was removed, two methods are available to configure your project:
Using the FileMaker PHP method: setProperty('name', $value), which can be used to individually configure the different parameters of the project;
Use a parameter array directly when creating the FileMaker object, for example: new FileMaker($db, $host, $user, $pass, ['dateFormat' => 'd/m/Y']) to configure the project in one single instruction.
Here is an example code illustrating all this:
[code language=”php”]
// Load the API
require_once (‘/path/to/API/autoload.php’);
// define name space
use airmoi\FileMaker\FileMaker;
$fm = new FileMaker($db, $host, $user, $pass, $options);
// Get a layout and test
$layout = $fm->getLayout(‘sample’);
if (FileMaker::isError($layout)) {
echo "Error: " . $layout->getMessage();
exit;
}
// Get a record
$record = $result->getFirstRecord();
if (FileMaker::isError($record)) {
echo "Error: " . $record->getMessage();
exit;
}
// Modify a record
$record->setField(‘text_field’, str_repeat(‘a’, 51));
$record->commit();
if (FileMaker::isError($record)) {
echo "Error: " . $record->getMessage();
exit;
}
[/code]
The old error management system is obtained by setting the “errorHandling” parameter to the “default” value.
As you can see, it forces you to repeat your controls for virtually every instruction.
Error Management: The Exception Method
[code language=”php”]
// Exception mode is configured by default
// no need to specify it
$fm = new FileMaker($db, $host, $user, $pass);
try {
// Try to get a layout
$layout = $fm->getLayout(‘sample’);
// Get a record (in 1 line)
$record = $fm->newFindAnyCommand(‘sample’)->execute()->getFirstRecord();
// Modify record
$record->setField(‘text_field’, str_repeat(‘a’, 51));
$record->commit();
} catch (FileMakerException $e) {
// Trap errors that can have occurred on any line
printf (‘Error %d : %s ‘, $e->getCode(), $e->getMessage());
}
[/code]
As you can see, exception handling via the try / catch block can significantly reduce the number of lines of code.
All its logic can be centralized, which simplifies the reading of the code, improves its reliability and its maintenance.
Now, with this new API, you can ask which data interval to retrieve. For example, you can request to have the data corresponding to the records from 5 to 25. This allows to obtain a pagination on a script result, which was impossible before.
Very handy feature because it now allows to define a global field at the time of the execution of a query, which will allow you for example to recover, in your results, related data through a global field.
Conclusion
As explained at the beginning of the article, FileMaker’s PHP API really needed a fresh start to adapt to the evolution of the latest technologies, especially regarding the interaction with modern PHP frameworks.
This rewriting required many hours of work and countless tests. The result is more than encouraging as this new version is now used daily in production on several professional projects managed by the 1-more-thing team.
But, although it is in the stable and mature state to be used in production, this rewrite is not yet finished, many other improvements are in progress and others to predict. If you want to contribute to its evolution, you are obviously welcome: GitHub Repository.
Many thanks to all those who participated, directly or indirectly, in the realization of this project, and a special thanks to Matthias Kühne for all his contributions.







 Hi Fabrice
Hi Fabrice